update 执行流程
本文内容
前言
在基础篇中知道了 select 语句执行的那套流程,一条 update 语句其实也会同样走一遍。
1. update 执行流程
先从全局的角度看看一条 update 语句的执行流程,之前的流程都和 select 相同,下面的流程从负责具体执行的执行器开始:
执行器 通过引擎取到需要修改的那一行,如果该行在内存(Buffer Pool)中,则直接返回给执行器,否则先从磁盘加载进内存,再返回;
执行器拿到行数据,执行更新操作,得到新行。再调用存擎接口写入该新行;
其实这里在执行更新操作前,还会记录旧数据的 undo log,用于回滚。
引擎将这行 新数据更新到内存,同时将更新操作记录到 redo log,此时 redo log 处于 准备 prepare 状态。然后告知执行器执行完成,随时可以提交事务;
执行器记录这个操作的 binlog,并把 binlog 写入磁盘;
执行器调用引擎接口提交事务,引擎这时才把 redo log 改成 提交(commit)状态,更新完成。
整个过程图如下:
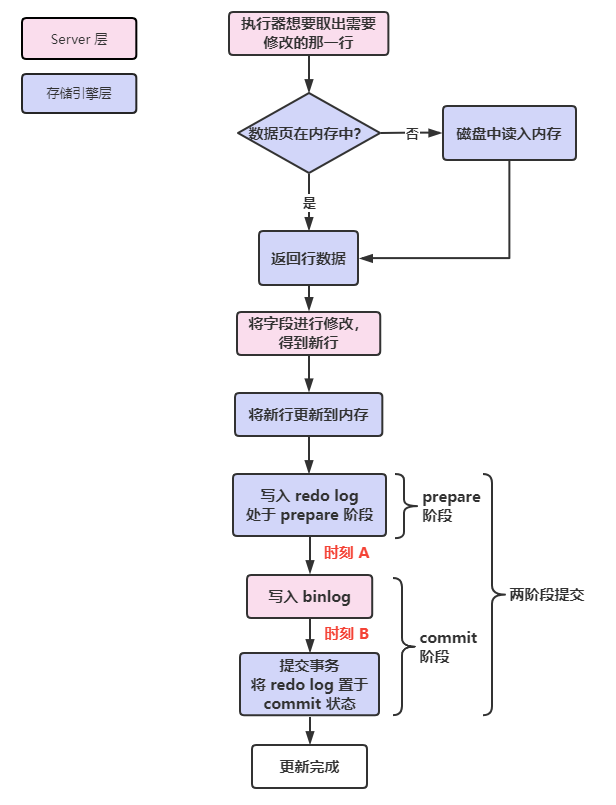
最后有关 redo log 和 binlog 的步骤涉及到 两阶段提交,下面就来详细地看看为什么需要这个两阶段提交。
2. 两阶段提交
2.1 不用两阶段提交会有什么问题?
事务提交后,redo log 和 binlog 都需要持久化到磁盘,但 这两个刷盘操作是独立的逻辑,所以可能出现半成功状态,这就会导致 两份日志的逻辑不一致。
如果不用两阶段提交,要么先写 redo log 再写 binlog ,要么反过来。那就来看看这两种方式在更新时会有什么问题:
先写 redo log 后写 binlog:假设在 redo log 写完后,此时 binlog 还没写完,MySQL 崩溃重启。由于 redo log 有 crash-safe 能力,所以可以把该数据的更新恢复回来。
但是由于 binlog 还没写完,因此 binlog 中没有该数据,因此在备份时就会漏了该数据的更新操作,在主从复制中,从库也会少了该数据的更新,造成主从数据不一致。
先写 binlog 后写 redo log:假设在 binlog 写完后崩溃重启,由于 redo log 还没写,因此崩溃恢复时不会恢复该数据的更新。
但是由于 binlog 已经记录了该数据的更新,所以在备份和主从复制时也会出现数据不一致的情况。
可以看到,如果不使用两阶段提交,那么数据库的数据就有可能和用它的日志恢复出来的库的数据不一致。因为 redo log 影响主库,binlog 影响备份恢复或从库。
所以,MySQL 为了保证两份日志的逻辑一致性,使用了「两阶段提交」,两阶段提交属于分布式事务一致性协议的内容,它可以保证多个逻辑操作要么全部成功,要么全部失败,不会出现半成功的状态。
2.2 两阶段提交如何保证两份日志的一致性?
既然更新记录可能会在一份日志中存在,在另一份日志中不存在,那么我们只要保证 同时存在或同时不存在,即可保证两份日志的一致性。
两阶段提交是这样做的:它把事务的提交分为了 2 个阶段,分别是「准备(Prepare)阶段」和「提交(Commit)阶段」。
注意 Commit 阶段和 commit 语句的区别,commit 语句执行时会包含 Commit 阶段)。
事务提交时,两阶段提交流程如下:

从上图可知,两阶段提交 将 redo log 的写入拆成了两个步骤:prepare 和 commit,中间再穿插写入 binlog:
- prepare 阶段:写入 redo log,将 redo log 对应的事务状态设置为 prepare;
- commit 阶段:写入 binlog,然后写入 binlog,接着调用引擎的提交事务接口,将 redo log 状态设置为 commit,两阶段提交完成。
可以发现,只要 binlog 写入成功,就算 redo log 还未刷盘,也会完成事务,那么这样能确保数据一致吗?我们下面来分析一下。
在两阶段提交过程中,发生崩溃后可能出现不一致的时刻 无非就两个:

- 时刻 A:写入 redo log 后,binlog 还未写入磁盘;
- 时刻 B:redo log 和 binlog 都写入了,但 redo log 还未写入 commit 标识。
两种情况 redo log 都处于 prepare 状态。
如果 redo log 处于 commit 状态,则说明两份日志都写入成功了,则直接恢复。
如果 redo log 里 只有 prepare 状态,则会判断 对应的事务 binlog 是否存在且完整:
- 如果是,则提交事务,进行恢复;
- 否则,回滚该事务,再进行恢复;
注意:这种情况需要把 innodb_flush_log_at_trx_commit 设置成 1,让事务执行提交操作时,即在 prepare 状态时,就会将 redo log 持久化一次,这样 崩溃恢复时才能在文件中找到 redo log。
如何判断 binlog 是否完整呢?
一个事务的 binlog 如果完整,那么会有一个标志:
- statement 格式的 binlog 最后会有 COMMIT 标志;
- row 格式的 binlog 最后会有一个 XID event。
怎么找到 redo log 对应的 binlog 呢?
其实,它们有一个 共同的字段 XID(内部 XA 事务的 ID),崩溃恢复时,会按顺序扫描 redo log:
- 如果碰到既有 prepare、又有 commit 的 redo log,则直接提交该事务;
- 如果碰到只有 prepare、而 没有 commit 的 redo log,就 拿着 XID 去 binlog 找到对应的事务,根据上面完整性的判断,来确定提交还是回滚该事务。
可以发现,通过对比 redo log 和 binlog,就能做到要么这个事务在两份日志中都有,要么都没有,从而保证了 一致性。
那么,为什么处于 prepare 状态的 redo log,加上完整的 binlog,重启后就能将事务提交进行数据恢复呢?
因为在上面的时刻 B,也就是 binlog 写完后发生崩溃,这时候 binlog 已经写入磁盘了,因此之后就会被从库(或用这个 binlog 恢复的库)使用,所以主库当然也要提交该事务,这样才能保证数据一致。
而如果 binlog 没有写入成功,那么之后也就不会被从库(或使用这个 binlog 恢复的库)使用,所以主库也不能要这些数据。
所以说,两阶段提交是以 binlog 是否写成功作为事务提交成功的标识,因为 binlog 写成功了,就意味着能在 binlog 中查找到与 redo log 相同的 XID。
如果事务还未提交时,redo log 就已经被持久化了,会有问题吗?
我们知道,事务执行过程中,redo log 是直接写到 redo log buffer 中的,而 redo log 的刷盘时机还有一个 后台线程每隔 1 秒,所以 会存在事务还未提交时,redo log 就已经被持久化了。
如果这时候发生了崩溃,会有一致性问题吗?
答案是 没有,此时还未提交的 redo log 会进行回滚,因为此时事务还未提交,说明 binlog 还未刷盘(binlog 只有事务提交时才会进行刷盘)。
所以, redo log 可能会在事务未提交之前持久化到磁盘,但是 binlog 必须在事务提交之后,才会持久化到磁盘。
另外,我们其实可以把 MySQL 的两阶段提交看成是两个分布式服务处理两个不同事情:
- 因为 redo log 在引擎操作,binlog 是在 Server 层操作,所以可以把引擎层和 Server 层看成两个分布式服务,它们要进行两个相关联的操作,就意味着要实现分布式事务,而两阶段提交,就是其中的一种解决方案。
3. 总结
再来回顾一下 update 语句的执行流程:
其中涉及到一个比较重要的 两阶段提交,它确保了两份日志的逻辑一致性,也就保证了主从库(或主库与备份库)的数据一致性。
两阶段提交是 以 binlog 是否写成功为判断依据,来选择主库的 redo log 是进行提交还是回滚。
4. 参考文章
- 《MySQL 实战 45 讲》
- 小林 coding