行锁的加锁规则
本文内容
前言
上一篇文章 中,介绍了 MySQL 中的锁类型,其中行级锁分为 Record Lock、Gap Lock 和 Next-Key Lock,那一条 SQL 语句要加行级锁时,应该加那个锁?具体是怎么加的呢?本文就来讲讲 MySQL 行级锁的加锁规则是怎样的。
1. 行级锁回顾
详细看 MySQL中的锁,下面只简单回顾几个重要的点。
什么情况需要加锁:
- 快照读(也就是简单 select 语句)无需加锁,通过 MVCC 来实现各种隔离级别;
- 当前读(显示给 select 语句加锁)以及增删改才需要加锁,并且获取到的是数据的最新版本。
行级锁分类:
- Record Lock:记录锁,只锁一条记录;
- Gap Lock:间隙锁,锁一个区间(前开后开);
- Next-Key Lock:临键锁,是 Record Lock 和 Gap Lock 的组合,锁区间为前开后闭。
2. 行级锁加锁规则
MySQL 中,加锁的基本单位是 Next-Key Lock,但是在某些情况下,会退化为 Record Lock 或 Gap Lock。
这些情况可以大致分为以下几种:
- 唯一索引的等值查询;
- 唯一索引的范围查询;
- 非唯一索引的等值查询;
- 非唯一索引的范围查询。
下面就来看看这些情况具体都加了什么锁,需要注意的时,Gap Lock 只有在可重复读隔离级别下才会出现,这也是 MySQL 的默认隔离级别,所以以下实验都是基于可重复读隔离级别的。
实验表如下,id 字段为主键索引(唯一索引),a 字段是普通索引(非唯一索引):
-- ----------------------------
-- Table structure for table
-- ----------------------------
DROP TABLE IF EXISTS `table`;
CREATE TABLE `table` (
`id` int NOT NULL,
`a` int DEFAULT NULL,
`b` int DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `index_a` (`a`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
-- ----------------------------
-- Records of table
-- ----------------------------
BEGIN;
INSERT INTO `table` (`id`, `a`, `b`) VALUES (1, 1, 1);
INSERT INTO `table` (`id`, `a`, `b`) VALUES (5, 5, 5);
INSERT INTO `table` (`id`, `a`, `b`) VALUES (10, 10, 10);
INSERT INTO `table` (`id`, `a`, `b`) VALUES (15, 15, 15);
COMMIT;
2.1 唯一索引等值查询
当使用唯一索引进行等值查询时,分为记录是否存在两种情况:
当查询的 记录存在 时,对该记录加的 Next-Key Lock 会 退化为 Record Lock;
当查询的 记录不存在 时,会 找到第一条大于该查询条件的临界记录,然后将这条临界记录加的 Next-Key Lock 退化为 Gap Lock(因为加的 Gap Lock 能保证该查询的记录不会被其他事务插入)。
Next-Key Lock 前开后闭,相当于把后闭去掉了,只锁区间。
记录存在情况
执行下面语句:
BEGIN;
SELECT * FROM `table` WHERE id = 1 FOR UPDATE;
# 不提交事务,锁在事务提交时会释放掉
然后进入 MySQL 客户端,使用下面命令来看具体加了什么锁(或者直接查看 performance_schema 数据库下的 data_locks 表):
mysql> SELECT * FROM performance_schema.data_locks\G;

- LOCK_TYPE 中,TABLE 表示表级锁,RECORD 表示行级锁;
- 在行级锁中,LOCK_MODE 中,会有如下数值,用来判断具体加的是行锁中的哪一类:
LOCK_MODE: X,加的是 Next-Key Lock;LOCK_MODE: X, REC_NOT_GAP,加的是 Record Lock;LOCK_MODE: X, GAP,加的是 Gap Lock;
- LOCK_DATA 表示加锁的记录,如果记录不存在,则表示加锁范围的右边界。
通过上面分析可以发现,是在 1 这条记录上加的 Record Lock,锁住的是这一条记录。
记录不存在情况
执行下面语句:
BEGIN;
SELECT * FROM `table` WHERE id = 3 FOR UPDATE;
看看加了什么锁:

可以发现是 在 5 这条记录(第一条比 3 大的记录)上加的 Gap Lock,因此锁住的区间是 (1, 5)。
2.2 唯一索引范围查询
当进行唯一索引的范围查询过程中,对扫描到的记录都会加 Next-Key Lock,然后也会根据不同情况进行退化。
我们可以将范围查询分为大于、大于等于、小于、小于等于,下面就按这四种情况来做实验,看看都加了什么锁。
大于情况
执行下面这条语句:
BEGIN;
SELECT * FROM `table` WHERE id > 5 FOR UPDATE;
看看加了什么行级锁:
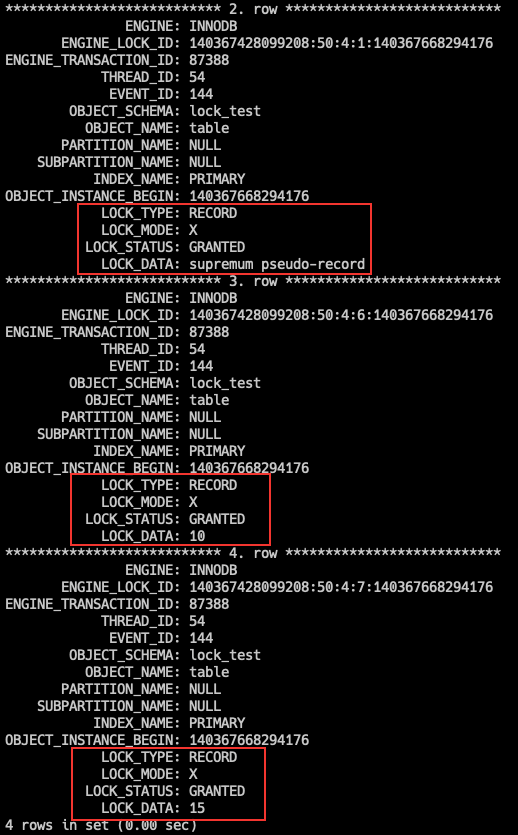
Tip:我们的表中最后一条记录是 id = 15 的,但是 InnoDB 会用一个特殊的记录来标识最后一条记录,这条记录就是 supremum pseudo-record。
可以发现加了如下几把锁:
- 10 这条记录上加了 Next-Key Lock,锁区间为 (5, 10];
- 15 这条记录上加了 Next-Key Lock,锁区间为 (10, 15];
- supremum pseudo-record 这条记录上加了 Next-Key Lock,锁区间为 (15, +∞]。
具体的加锁过程是:
- 要查找到 id 大于 5 的第一行记录,对该记录加 Next-Key Lock;
- 由于查询条件是大于,所以会继续往后扫描,扫描到的记录都会加锁,而且加的都是 Next-Key Lock。
加 Next-Key Lock 可以保证在 id > 5 的范围中,Gap Lock 确保其他事务不会插入 id > 5 的新记录,Record Lock 确保其他事务不会修改 id > 5 的已存在记录。这样才能 在 RR 隔离级别下,避免幻读(不是完全)和不可重复读问题。
所以,在遇到唯一索引的范围查询时,如果查询条件是大于,会将大于的记录都加上 Next-Key Lock,不会有任何退化。
大于等于情况
执行下面这条语句:
BEGIN;
SELECT * FROM `table` WHERE id >= 5 FOR UPDATE;
加锁情况如下:

可以发现,除了有一条 Record 锁外,其他锁都和大于一样。
也可以很容易想到,由于有了等值查询,因此需要把等值的这条记录给锁上,而该记录之前的范围(id 小于 5 的范围)又没必要锁,因此就退化为 Record Lock,只锁这一条记录。
那如果 等值记录不存在呢?来看看:
BEGIN;
SELECT * FROM `table` WHERE id >= 6 FOR UPDATE;
加锁情况:

可以发现,这时候就和大于是一样的了,由于 id = 6 这条记录不存在,没办法只锁这一条记录,所以只能把区间 (5, 10] 都上锁了。
小于情况
执行下面的语句:
BEGIN;
SELECT * FROM `table` WHERE id < 10 FOR UPDATE;
加锁情况:

记录 1 上加了 Next-Key Lock,锁范围是 (-∞, 1];
InnoDB 中也有一条特殊的记录 infimum record,表示最小记录。
记录 5 上加了 Next-Key Lock,锁范围是 (1, 5];
记录 10 上加了 Gap Lock,锁范围是 (5, 10)。
加锁步骤如下:
首先扫描到的是记录 1 和记录 5,它们都比 10 小,因此加的是 Next-Key Lock;
再往后扫描到记录 10,此时扫描就停止了,因为 该记录是第一条不满足查询条件(id < 10)的记录。
由于条件不是等值查询,没必要锁该记录,因此需要将 Next-Key Lock 退化为 Gap Lock。
如果 查询条件的记录不在表中,也是同理,找到第一条不满足查询条件的记录,然后该记录加的是 Gap Lock,前面的记录全都加 Next-Key Lock 即可。
小于等于情况
执行的语句如下:
BEGIN;
SELECT * FROM `table` WHERE id <= 10 FOR UPDATE;
加锁情况:
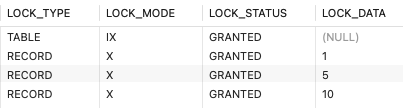
此时就很好分析了,跟小于情况类似,但由于有等值条件,所以 id = 10 这条记录的 Next-Key Lock 就不能退化成 Gap Lock 了。
再来看看等值条件不在表中的例子:
BEGIN;
SELECT * FROM `table` WHERE id <= 12 FOR UPDATE;
加锁情况:

由于 要扫描到第一条不满足条件的记录,所以会扫描到 id = 15 这条记录,而这条记录是没有必要加 Record Lock 的(与我们的条件无关),因此退化为了 Gap Lock。
2.3 非唯一索引等值查询
首先提醒一点,在加锁时,只要扫描到的记录都会加锁,所以如果需要回表查主键索引时,不仅会在二级索引上加锁,也会在主键索引上加锁,
接下来就来看看非唯一索引的等值查询是如何加锁的,也分为等值查询的条件记录是否存在:
当等值查询的条件 记录存在 时,由于不是唯一索引,所以需要像范围查询那样进行 扫描,首先找到第一条符合条件的,然后加上 Next-Key Lock,直到查找到第一条不符合条件的记录(临界记录)。这个扫描过程中,会对符合条件的二级索引记录加 Next-Key Lock,临界记录上的锁会退化为 Gap Lock。
与此同时,由于 等值查询的条件记录存在,所以需要在符合查询条件记录的主键索引上加 Record Lock,来防止主键索引上的记录被修改。
当等值查询的条件 记录不存在 时,基本和上面类似,只是不需要在主键索引上加锁了。
我们先在数据库中加入一条非唯一索引值相同的记录:

记录存在
执行语句如下:
BEGIN;
SELECT * FROM `table` WHERE a = 10 FOR UPDATE;
加锁情况:

LOCK_DATA 包含了索引列和主键列。
这里要注意看 INDEX_NAME,看在哪个索引上加了锁:
- 在二级索引上,定位到该查询条件的首条记录,加上 Next-Key Lock。继续向后扫描,直到找到第一个不满足条件的记录(扫描过程对符合添加的记录都加的是 Next-Key Lock);
- 找到临界记录后,即
a = 15的记录,由于不用锁该记录,因此锁会退化为 Gap Lock; - 由于扫描过程中扫描到的有两条记录,所以在主键索引中需要对这条件记录加 Record Lock。
加锁图示如下:

也很好理解,由于非唯一索引可能会在缝隙中插入索引列相同的记录,所以肯定要把每个缝隙都锁上,而且两边也要有 Gap Lock。
记录不存在
再来看看记录不存在的情况:
BEGIN;
SELECT * FROM `table` WHERE a = 12 FOR UPDATE;
加锁情况:

此时就比较简单了,扫描到第一条不满足条件的记录,也就是 a = 15,加一个 Gap Lock 即可保证不会在 (10, 15) 区间插入符合查询条件的记录。
2.4 非唯一索引范围查询
在非唯一索引的范围查询中,对二级索引加的都是 Next-Key Lock,不会有退化的情况。因为等值条件情况下,也有可能会插入相同的记录,所以 Record Lock 是必须的。
下面举个例子:
BEGIN;
SELECT * FROM `table` WHERE a >= 10 FOR UPDATE;
加锁情况:

图示:

若是 a > 10,则会从第一条符合条件的记录(a = 15)开始加锁,然后向后扫描,逐一加锁。
再来看个小于的例子:
BEGIN;
SELECT * FROM `table` WHERE a < 10 FOR UPDATE;
加锁情况:

扫描到第一个不满足 a < 10 的记录停止。
3. 总结
所有情况都做完实验后,可以发现,加锁是根据具体情况来加的,在不需要时尽力退化,减小锁的力度。
在分析加行锁时,所需的一些前置知识总结如下:
行锁的类型有 Gap Lock、Record Lock 和 Next-Key Lock(Gap + Record):
- Gap Lock 锁范围是前开后开;
- Next-Key Lock 锁范围是前开后闭;
- 某条记录上有 Gap 锁时,该记录是=属于后区间。
加锁的基本单位是 Next-Key Lock;
在唯一索引上加锁时,由于不存在重复的索引字段,因此某些情况可以将 Next-Key 退化:
- 等值查询时:
- 如果查询条件的记录存在,那么该记录的锁可退化为 Record Lock;
- 否则,需要查找到第一条不满足条件的记录,然后对该记录加的锁可以退化为 Gap-Lock。
- 范围查询时:
- 如果是大于,则需要从满足该查询条件的记录开始,往后扫描,不断加锁;
- 如果是小于,则从前往后一直扫描,一直加锁,直到扫描到不符合查询条件的第一条记录,该条记录的锁可退化为 Gap Lock,因为没必要锁这条不满足查询条件的记录;
- 如果是 >= or <=,那么在扫描到等值查询条件时,也会对锁进行退化。
- 等值查询时:
非唯一索引的分析思路其实都一样,只要记住非唯一索引可能存在索引列相同的情况即可。