select 执行流程
本文内容
前言
对于一个 CRUD Boy,每天最多使用的 SQL 语句非 select 莫属了吧。那么你知道一条 select 语句是如何执行的吗?
下面就以最常见的 MySQL 为例,来探究探究一条 select 语句到底要历经哪些坎坷,才能把数据呈现给我们。
1. 客户端连接服务器
想要执行 select 语句,首先肯定要与 MySQL 服务器进行连接,这个连接是通过 连接器 来完成的。
首先,运行中的服务器程序和客户端程序本质上都是计算机上的一个进程,所以客户端与服务器连接的过程本质上就是 进程间通信 的过程。
在 Linux 中,进程间的通信方式有管道、共享内存、信号量、消息队列、Socket 通信等。前面的几种都是在同一台主机上进行通信,如果需要跨网络与不同主机的进程进行通信,则需要使用 Socket 通信。
ps:Socket 也支持同主机上的进程间通信。
在真实环境中,数据库服务器进程和客户端进程大概率是不在同一台主机上的,所以需要通过网络进行通信。
MySQL 采用的 Socket 类型是 TCP 字节流通信,MySQL 服务器在启动时会默认申请 3306 端口号,之后就在这个端口号上等待客户端进程的连接。
我们一般使用如下命令与 MySQL 服务器进行连接:
mysql -h$ip -u$username -P$port -p$password
-h:MySQL 服务器的 IP 地址,如果是本地连接可以省略;-u:用户名,管理员为 root;-P:指定端口号(注意是大写),使用默认端口可以省略;-p:连接密码(注意是小写),命令中可以不填(比较安全),在交互对话中进行填写。
发起上面的命令后,就会进行 TCP 三次握手与服务端建立连接,然后就会校验客户端输入的用户名和密码,校验成功后就连接成功了,接下来就可以与 MySQL 服务器进行通信了,即可以发送 SQL 语句了。
客户端连接到 MySQL 后,一直不发起请求,会怎么样?
先来了解一下数据库里的 长连接 和 短连接:
- 长连接:连接成功后,如果客户端有 N 个请求,则都会 复用 一个连接;
- 短连接:每次执行完几次请求就断开连接,下次请求需要 重新建立 一个连接。
建立连接的过程是比较复杂的,因此我们一般都是使用 长连接。
在长连接的情况下,连接完成后,如果客户端没有任何操作,那么连接器就会 自动断开连接。这个时间由参数 wait_timeout 控制,默认值是 8 小时。
连接器断开连接后,如果客户端再次发送请求,就会收到一个错误提醒:Lost connection to MySQL server during query。这时候就需要重新建立连接,再发送请求。
长连接的缺陷:可能会导致 MySQL 占用的内存涨的非常快。因为 MySQL 在 执行过程中临时使用的内存是管理在连接对象里面的,这些资源 在连接断开时才会释放。所以长期累积下来,可能导致内存占用太大,被 OS 强行杀掉(OOM),看来是就像是 MySQL 异常重启了。
解决方案:
- 定期断开长连接。
- 每次执行一个较大的操作后,通过 执行
mysql_reset_connection来初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
2. select 执行流程
建立连接后,便可向 MySQL 服务器执行 SQL 语句,获取结果。
先从整体的角度来看看一条 select 请求会经历哪些过程,如下图所示:
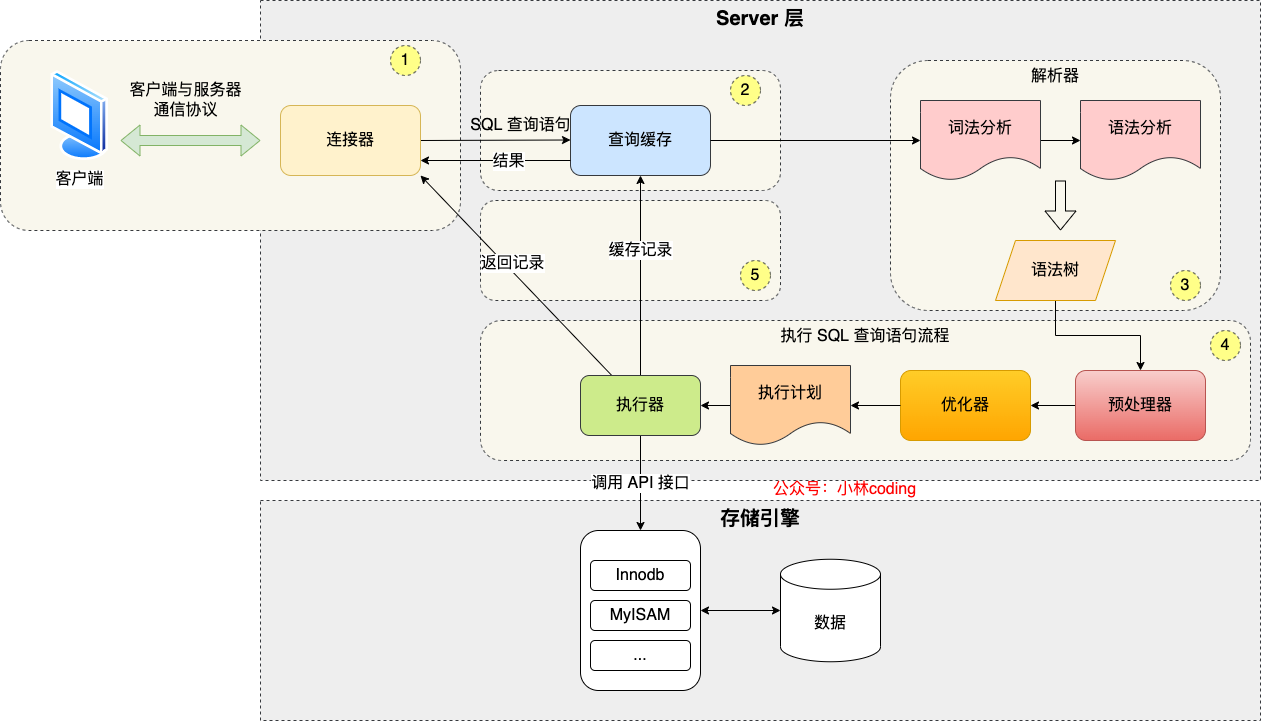
从上面可以看出一条 select 语句大致的执行流程如下:
首先会去 查询缓存 里面看之前是否执行过这条语句。查询缓存以 kv 形式存储在内存中,key 为 SQL 语句,value 为查询结果;
注:由于缓存命中率不高,所以查询缓存在 MySQL 8.0 已移除。
来到 解析器,主要是进行 SQL 语法的分析,生成对应的语法树;
再到 执行器 执行 SQL 语句,不过在执行之前,会先经过 预处理器(判断字段是否存在)和 优化器(基于成本生成执行计划);
最后执行器会按照执行计划调用 存储引擎层,由存储引擎去真正地访问表中的数据;
执行器获取到查询结果,返回给客户端。
可以发现,MySQL 执行请求的过程被划分为了 Server 层 和 存储引擎层。Server 层不涉及真实数据的存取,而存储引擎层具有存取真实数据的功能。
接下来就看看各个阶段主要做了什么事情。
2.1 查询缓存
上面说到,在 MySQL 8.0 中已移除了查询缓存,来看看为什么呢?
查询缓存的设计是这样的:
- 将之前查询的 SQL 语句作为 key,查询结果作为 value 存放在内存中;
- 新的查询会先经过查询缓存,通过 Hash 索引判断缓存是否命中,若命中则可直接返回缓存结果。
这看上去和常见的缓存类似,没什么问题。但是查询缓存的 更新策略 是这样的:
- 如果这张表有 更新操作,那么这个表的 所有查询缓存就会被清空。
由于这种更新策略,当刚缓存了一系列的数据时,还没被使用呢,刚好这个表有个更新操作,那么这个缓存也就被清空了。
正是因为更新会导致查询缓存的命中率非常低,所以 MySQL 8.0 直接将查询缓存删除了。
2.2 解析阶段
查询缓存被删除后,SQL 语句的第一站就是 解析器,它会对 SQL 语句做解析。主要做两件事:
- 根据 SQL 语句 构建出语法树,方便后面获取 SQL 语句的类型、表名、字段名、where 条件等;
- 判断 SQL 语句是否满足 MySQL 的语法,即 检查是否有 SQL 语法错误。如果有误则会报错。
不过需要注意,表不存在或者字段不存在,不是在解析器里判断的,而是在下面的执行阶段做的。
2.3 执行阶段
通过了解析阶段后,SQL 语句就来到了执行阶段,每条 select 语句在执行阶段主要会经历以下三个阶段:
- prepare:预处理阶段;
- optimize:优化阶段;
- execute:真正的执行阶段。
阶段一:预处理阶段
在预处理阶段,预处理器 主要做两件事:
- 判断表是否存在或字段是否存在;
- 将
select *中的*替换为表上所有的列。
阶段二:优化阶段
在真正执行一条 select 语句之前,MySQL 在优化阶段的 优化器 会找出所有可以用来执行此语句的方案,然后 选择一个成本最低的方案,作为执行计划。
如果想要知道优化器选择了哪种方案,可以在 SQL 语句前加上 explain 命令,让它输出 SQL 语句的执行计划,执行计划中会有扫描方式、使用的索引等信息。
在 MySQL 中执行成本主要由两个方面组成:
- I/O 成本:当我们的数据是存储在磁盘上时,需要将数据从磁盘加载到内存中,这个加载时间就称为 I/O 成本;
- CPU 成本:读取记录、判断记录是否满足搜索条件、对结果进行排序等等操作消耗的时间称为 CPU 成本;
阶段三:真正的执行阶段
选择出成本最低的执行方案后,才开始真正的执行阶段,执行阶段由 执行器 完成。
在执行的过程中,执行器会调用存储引擎层的 API,和存储引擎交互,交互是以记录为单位的。
存储引擎层 每查出一条记录,就要返回给 Server层判断该记录是否满足查询条件(每查询出一条记录就要返回判断):
满足条件则将记录发送给客户端;
是的没错,Server 层每从存储引擎读到一条符合条件的记录就会发送给客户端,之所以客户端显示的时候是直接显示所有记录的,是因为客户端是等查询语句查询完成后,才会显示出所有的记录。
不满足则跳过,继续读取下一条记录。
当存储引擎把把表中的记录都读完时,就会像执行器返回读取完毕的信息,执行器收到后,就会停止查询。
停止查询后,执行器会提示客户端已经完成了查询操作,客户端就会显示出所有的查询记录了。
一条 SQL 语句到此也就执行完毕了。
3. 总结
通过了上面的学习,现在应该知道一条 select 语句经历了哪些:
- 查询缓存(MySQL 8.0 已移除):缓存命中则直接返回结果,否则继续往下走;
- 解析阶段:解析器对 SQL 进行语法解析,生成语法树、判断语法是否有误;
- 执行阶段:
- 预处理阶段:检查表或字段是否存在,将
*替换成所有列; - 优化阶段:基于成本选择最优的执行计划;
- 真正执行阶段:执行器根据执行计划从存储引擎读取记录,返回给客户端;
- 预处理阶段:检查表或字段是否存在,将
现在再来回看一开始的那张图,是不是就清晰多了:
4. 参考文章
- 《MySQL 是怎样运行的》
- 《MySQL 实战 45 讲》
- 小林 coding