什么是服务注册与发现
本文内容
前言
想要构建微服务、注册服务,首先要解决的是 服务提供者如何发布服务,服务消费者如何引用服务。即 上一章 中所讲的 服务的接口名是什么?传递的参数是什么?返回值是什么?和一些接口描述信息等。
回顾一下,常见的服务发布和引用的方式有 RESTful API、XML 配置和 IDL 文件(Interface Definition Language)三种。
我们定义好服务后,如何让调用者知道该服务的地址呢?也就是怎么知道该服务部署到哪台服务器上的?这就需要引入一个第三方了,即 服务注册与发现中心。
1. 什么是服务注册与发现
为什么需要服务注册与发现呢?在微服务架构中,我们的服务在定义好后,都是 部署到不同的服务器上的,各服务监听着不同的端口。那客户端在请求服务时,怎么知道该服务对应的服务器是哪个呢?

就好比你去吃 KFC,你怎么知道你所在的区域哪儿有 KFC?此时一般都会用 App 搜一下附近的 KFC 店。那 App 上为什么会有这家 KFC 店呢?那肯定是这家店提前在 App 上注册了嘛,在注册的时候,KFC 就会把自己的店铺地址告诉 App,这样你就能通过 App 找到这家 KFC 了。
这就是服务注册与发现模型了,在上面的例子中,你扮演着客户端,KFC 扮演着服务端,而 App 则扮演着注册中心。
在分布式系统中,服务注册与发现 就是指:服务端将服务部署的地址记录到注册中心,客户端需要调用服务时,先去注册中心查询到该服务名对应的地址,然后向服务端发起请求即可。
服务注册与发现的基本模型如下:

在微服务架构下,主要有三种角色:服务端(服务提供者)、客户端(服务消费者)、服务注册中心。基于上面的模型,它们之间的交互关系如下:
服务端启动时,向服务中心注册自身信息,主要是定位信息;
注册成功后,注册中心和服务端要 保持心跳。
客户端第一次发起服务调用时,先去注册中心获取所有可用服务节点列表,接着客户端会在本地缓存每个服务对应的可用节点列表;
客户端和注册中心也要 保持心跳,以及 数据同步,服务端有变动时,注册中心会通知客户端,接着客户端会更新本地缓存。
后续客户端就可以直接向服务端发起请求了,服务端响应即可。
当服务端不再提供服务时,即 服务端下线时,过程如下:
服务端通知注册中心自己准备下线了;
注册中心通知客户端该服务端下线了;
客户端收到通知后,后续的请求便不会发送给该服务端了;
服务端需要等待一段时间后,便可暂停服务并下线。
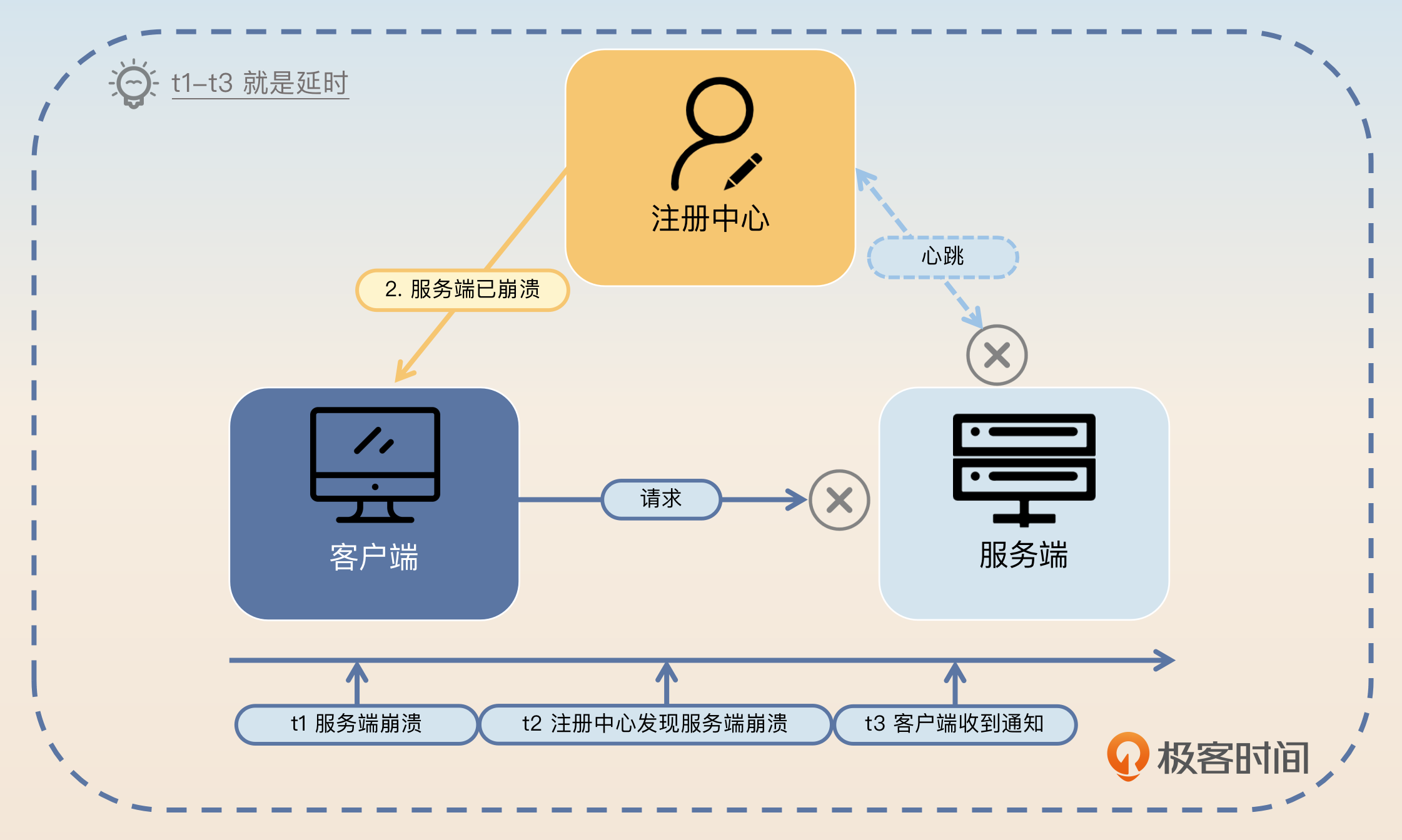
因为 从服务端通知注册中心,再到注册中心通知客户端,是有一段时延的,这段时延就是服务端需要等待的最短时间。

一些常见的服务注册与发现的组件有 Zookeeper、Eureka、Consul、Nacos 等,后续文章会讲解。
2. 高可用的服务注册与发现
服务注册与发现的整体模型还是比较简单的,但是要保证其 高可用性,还是有难度的。
高可用的服务注册与发现主要是围绕 服务端崩溃检测、客户端容错、注册中心选型 三个方面进行的。
2.1 服务端崩溃检测
在正常情况下,服务端下线会通知注册中心,但如果 服务端直接崩溃,就没法通知注册中心了,注册中心自然也不会通知客户端了,此时 客户端发给该服务端的所有请求就都会失败。
为了提高可用性,就需要让 注册中心尽快发现服务端已崩溃,然后才能通知客户端。那么注册中心怎么判断服务端已经崩溃了呢?
从上面的服务注册与发现基本模型可知,注册中心和服务端是维持了一个 心跳 的,所以我们可以由此得出:注册中心和服务端之间的心跳断了,就可以认为服务端已经崩溃了。
但是,注册中心和服务端一般是跨网络的,如果 网络出现抖动,心跳也会失败,而此时服务端并没有崩溃:

所以,只通过心跳断开来判断服务端崩溃是不合理的。此时你可能会想 多发几次心跳 不就行了?确实可以,但次数越多,注册中心判断服务端已崩溃的时间也越长,那么就会导致更多的请求发送给了服务端,而如果此时服务端是真的崩溃了,就会导致这些请求全都会失败。
那有没有什么能尽可能的保证高可用的方案呢?
首先,注册中心和服务端心跳失败时,注册中心可以 马上通知客户端该服务端已经不可用了,客户端暂时不会发请求过来。

其次,注册中心还要继续向服务端发送心跳:
如果只是因为网络 偶发性的心跳失败,则肯定能 心跳成功,此时注册中心再 通知客户端该服务是可用的;
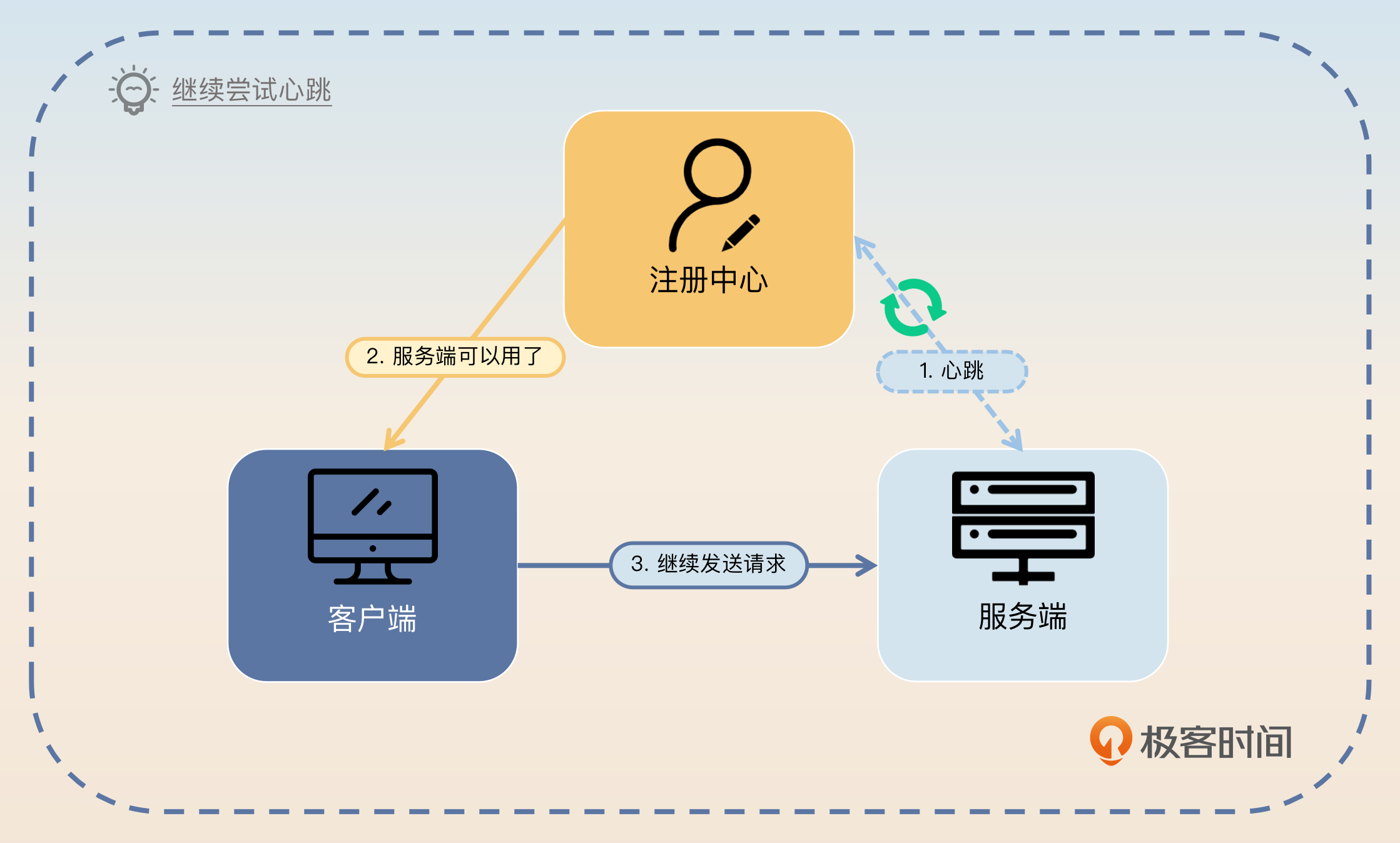
如果服务端真 崩溃,则心跳一段时间还是失败,注册中心也 无需做任何通知,因为一开始就通知过了。
小结
小结一下,影响服务注册与发现高可用的关键就是需要让注册中心尽快发现服务端已经崩溃了:
- 当注册中心与服务端的心跳失败后,就认为该服务端可能已经崩溃了,马上通知客户端停止使用该服务;
- 为了避免因网络问题导致的偶发性心跳失败,注册中心需要继续与服务端保持心跳:
- 如果几次都失败,则认为该服务彻底崩溃;
- 如果心跳恢复,注册中心再次通知客户端该服务是可用的即可。
其实通过心跳机制来判断节点是否崩溃本身也是个棘手的问题。比如 心跳失败了是否应该重试?是立刻重试还是间隔重试?重试几次?
在服务注册与发现中,为了解决偶发性心跳失败的问题,是必须要重试的,但如果重试,就涉及到上面的说道的棘手问题了:
- 如果 间隔重试,比如规定重试三次,每次间隔 10 秒,那么注册中心要确定服务端崩溃就需要 30 秒。这 30 秒内可能已经 有成千上万的请求发到崩溃的服务端了;
- 如果 立刻重试,而且不设置重试间隔,那么就 很难避免因网络抖动而引起的偶发性心跳失败。因为在第一次心跳失败后,网络恢复没这么快,所以立刻重试大概率也是失败的。
比较好的策略是 立刻重试和间隔重试相结合:
- 第一次心跳失败时,立刻重试几次;
- 如果立刻重试几次失败,则进行几次间隔重试;
所以我们需要设计合理的重试的次数和时间间隔,以确保我们的业务在可接收的范围内重试成功。
不过 从服务端崩溃到客户端知晓,中间始终都存在一个时延,这时候就需要 客户端自己来做容错了。
2.2 客户端容错
客户端容错指的是 在注册中心或服务端节点出现问题时,客户端尽量能将请求发送到正常的服务端节点上。
如何实现呢?其实很简单,在最开始讲服务注册与发现基本模型的时候说过,客户端在第一次请求时,会先向注册中心获取该服务对应的所有 可用服务节点列表,保存到本地缓存中。所以 客户端发现请求失败后,换另一个可用节点进行重试即可。
换节点「Failover」是常见的容错机制之一,意为失效转移。
所以,客户端可以在服务端崩溃,到注册中心发现,再到客户端收到通知的这个 时延内,可以 继续正常的进行请求,如果发现请求失败,那么就应该切换节点进行重试,在短时间内不再使用该节点,将该节点从列表中移除,后面再根据实际情况判断是否将该节点移回列表中:
- 如果注册中心最终发现该节点崩溃了,会通知客户端,那么客户端此时就不用移回了;
- 如果该节点后面恢复正常,那么注册中心会同步数据给客户端,此时客户端更新自己的可用节点列表即可。
但如果注册中心和服务端都是正常状态,只是客户端和服务端之间的网络出现问题,此时就需要 客户端主动检测了,即对服务端进行心跳测试。
2.3 注册中心选型
在注册中心选型上,主要是考虑分布式系统的 CAP 中,选 AP 还是 CP 的问题。
简单说一下 CAP:
- C:Consistency,数据一致性;
- A:Availability,服务可用性;
- P:Partition-tolerance,分区容错性。
在 CAP 理论中,一个分布式系统不可能同时满足 CAP,只能同时满足其中两个。
我们在对 注册中心选型 时,其实是 更倾向于选 AP 的,在大规模集群上,注册中心崩溃对系统的影响太大了,可能崩溃几秒就会导致成千上万的请求异常。
而且在注册中心中,放弃 C,也就是客户端可能会拿到一些错误的节点,但这可以通过客户端容错来解决。
如果是小规模集群,且系统对一致性要求比较高,例如金融场景,可以使用 CP。
下面给出几个常见的服务注册与发现组件的 CAP 选择:
- Zookeeper 和 Consul 都是 CP;
- Eureka 是 AP;
- Nacos 支持 AP、CP,可按需切换。
补充:注册中心崩溃了怎么办?
我们前面谈的都是服务端崩溃后,注册中心、客户端的高可用方案,那么如果是 注册中心崩溃 了,应该怎么保持系统的高可用呢?
其实也可以借鉴前面的思路,如果注册中心崩溃,可以分两种情况来说:
客户端调用已知服务:此时虽然注册中心崩溃,但 客户端的本地缓存中还有已知服务的节点地址列表,因此可以继续使用这个列表进行请求。如果发现有节点出现异常,则通过客户端的容错来切换到可用节点上即可;
客户端调用未知服务:此时属于第一次调用该服务,而注册中心又崩溃了,因此是拿不到节点列表的,所以只能不断重试,直到 注册中心恢复或切换注册中心节点 来获取节点列表后,才可继续请求。
所以说注册中心一般要保证 AP,如果注册中心不是高可用部署,此时就只能返回服务不可用了。
3. 总结
从服务注册与发现的引出,到其基本模型的解读可以发现,其实注册中心就是充当一个服务与节点列表的存放地。
其中最关键的是理解服务注册与发现的基本模型:
服务上线:
服务下线:
紧接着,谈到了如何保证一个服务注册与发现的 高可用,主要是围绕 心跳、客户端容错、切换节点、注册中心选型 这几个关键词进行分析的。