常见负载均衡算法
本文内容
前言
当通过注册中心获取到了某个服务的可用节点列表后,就可以对节点发起请求了。
但是,这个列表中一般都 包含了多个节点,那客户端应该选择哪一个呢?这就需要引入 负载均衡 了。
1. 负载均衡有什么用?
为什么要引入负载均衡呢?当客户端得到一个可用节点列表后,随便选一个不都可以请求成功吗?
是的,随便选一个也能保证服务能正常请求,但是我们需要考虑下面几点:
- 如果每次随便选择的节点都是同一个,那么该节点将会承受所有请求,导致性能下降甚至出现故障;
- 可用节点列表中的各节点的性能如果不同,那么选到一个性能低的节点则会导致请求耗时更长,这肯定不是客户端想要的;
- 随便选择节点可能会导致某些节点永远都选不到的情况,这样就无法发挥所有节点的作用了。
所以,引入负载均衡是很有必要的,负载均衡算法选的好,能让微服务项目 可用性更好、性能更强、机器的利用率更高,能为客户端选出 最合适的节点。
下面就来看看常见的负载均衡算法有哪些,我们又该如何选择?
2. 常见负载均衡算法
负载均衡算法分为两大类,分别是:
- 静态负载均衡算法:统计学上的 “最合适”,在系统运行期间不能动态切换到真正合适的节点;
- 动态负载均衡算法:能够 实时检测 的负载均衡算法,在系统运行期间能够实时判断候选节点的状态,从而选出此时最合适的节点。
常见的静态负载均衡算法有:轮询、加权轮询、随机、加权随机、哈希以及一致性哈希。
常见的动态负载均衡算法有:最少连接、最少活跃请求数、最快响应时间等。
下面我按照先静态负载均衡、后动态负载均衡的顺序,来讲讲这几种常用的算法。
2.1 轮询与加权轮询
轮询
轮询 是最简单、也最常用的负载均衡算法,它其实就是 按照顺序轮流的作为目标节点。
比如服务端一共有 3 个节点,那么客户端请求时,被选中的节点顺序就是 node1 -> ndoe2 -> node3 -> node1 -> ......
加权轮询
但是,由于每个节点的性能是不一样的,比如 CPU 频率、核数、内存大小等,所以我们可以 让性能高的节点多处理一些请求,这就是 加权轮询。
比如 node1 的性能比较高,我们将它的权重调为其他 2 个节点的三倍,那么 node1 被选中的次数也会是其他 2 个节点的三倍。被选中的节点顺序就是 3 次 node1 -> node2 -> node3 -> 3 次 node1 -> ......
但是,如果某个节点的权重倍数过大,加权轮询算法就会 导致多个请求都连续请求到一个节点,一旦该节点发生意外,后面连续几次请求也都会跟着失败。
平滑的加权轮询
为了解决这个问题,有个改进叫做 平滑的加权轮询算法,这个算法可以保证 在整体请求次数根据权重合理分配的前提下,让连续的请求依次分配给不同的节点。
平滑的加权轮询算法,每个节点会有两个权重,初始权重(initWeight)和 当前权重(currentWeight),算法步骤如下:
- 对每个节点,执行 currentWeight = currentWeight + initWeight;
- 将 currentWeight 最大的节点作为目标节点;
- 将目标节点的 currentWeight 修改为 currentWeight = currrentWeight - sum(initWeight),对所有节点的 initWeight 求和。
通过以上步骤,每个节点在被挑选后,currentWeight 就会下降,下一次就不会选中它,而经过几轮后,他的权重又会升回来。
我用 Python 简单的模拟了上面的步骤,可以看到每次请求都分配到了不同的节点上:
# 平滑的加权轮询算法
initWeight = {'node-1': 9, 'node-2': 6, 'node-3': 8, 'node-4': 10}
currentWeight = {'node-1': 0, 'node-2': 0, 'node-3': 0, 'node-4': 0}
hitNode = {} # 节点命中情况
hitNodeCnt = {} # 节点命中次数
initWeightSum = sum(initWeight.values())
def calculate():
for i in range(1, 41):
# 计算当前权重
for j in range(1, 5):
node = 'node-' + str(j)
currentWeight[node] += initWeight[node]
# 选出节点
max_value = max(currentWeight.values())
max_keys = [key for key, value in currentWeight.items() if value == max_value]
hit = max_keys[0] # 无论多少个 key,只选第一个(随机)
hitNode[i] = hit
hitNodeCnt[hit] = hitNodeCnt.get(hit, 0) + 1
# 扣减当前权重
currentWeight[hit] -= initWeightSum
if __name__ == '__main__':
calculate()
for k, v in hitNode.items():
print('轮次:', k, ',命中节点:', v)
print('============================')
for k, v in hitNodeCnt.items():
print('节点:', k, ',命中次数:', v)
输出:
轮次: 1 ,命中节点: node-4
轮次: 2 ,命中节点: node-1
轮次: 3 ,命中节点: node-3
轮次: 4 ,命中节点: node-2
轮次: 5 ,命中节点: node-4
轮次: 6 ,命中节点: node-1
轮次: 7 ,命中节点: node-3
轮次: 8 ,命中节点: node-2
轮次: 9 ,命中节点: node-4
轮次: 10 ,命中节点: node-1
轮次: 11 ,命中节点: node-3
轮次: 12 ,命中节点: node-4
轮次: 13 ,命中节点: node-1
轮次: 14 ,命中节点: node-2
轮次: 15 ,命中节点: node-3
轮次: 16 ,命中节点: node-4
轮次: 17 ,命中节点: node-1
轮次: 18 ,命中节点: node-4
轮次: 19 ,命中节点: node-3
轮次: 20 ,命中节点: node-2
轮次: 21 ,命中节点: node-1
轮次: 22 ,命中节点: node-4
轮次: 23 ,命中节点: node-3
轮次: 24 ,命中节点: node-1
轮次: 25 ,命中节点: node-4
轮次: 26 ,命中节点: node-2
轮次: 27 ,命中节点: node-3
轮次: 28 ,命中节点: node-1
轮次: 29 ,命中节点: node-4
轮次: 30 ,命中节点: node-2
轮次: 31 ,命中节点: node-3
轮次: 32 ,命中节点: node-1
轮次: 33 ,命中节点: node-4
轮次: 34 ,命中节点: node-4
轮次: 35 ,命中节点: node-1
轮次: 36 ,命中节点: node-3
轮次: 37 ,命中节点: node-2
轮次: 38 ,命中节点: node-4
轮次: 39 ,命中节点: node-1
轮次: 40 ,命中节点: node-3
============================
节点: node-4 ,命中次数: 12
节点: node-1 ,命中次数: 11
节点: node-3 ,命中次数: 10
节点: node-2 ,命中次数: 7
Process finished with exit code 0
可以发现,每次请求是比较平均的,没有连续请求一个节点的情况出现。
2.2 随机与加权随机
随机
随机就和我们开篇讲的一样,随便挑选一个节点即可。而加权随机则是通过权重来判断被选中的概率,权重越大,被选中的概率就越大。
比如,node1 权重为 30,node2 为 10, node3 为 10,那么当生成一个随机数(50 以内)后,落到它们的区间分为是:
- node1:20 <= 随机数 < 50;
- node2:10 <= 随机数 < 20;
- node3:10 <= 随机数。
2.3 哈希与一致性哈希
哈希
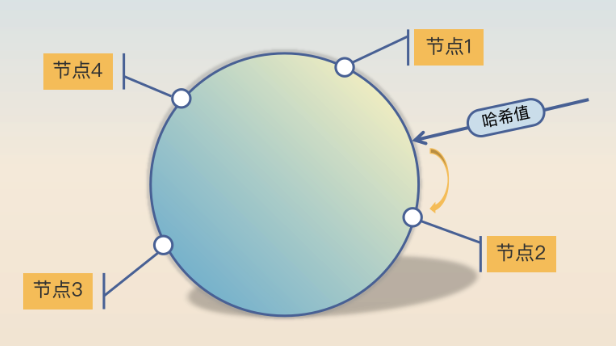
哈希 会选取请求中的某些参数来做 哈希计算得到一个哈希值,然后对节点数量取余,即可得到目标节点的编号。
比如下面:

可以发现,这和随机算法类似,只不过 哈希是通过固定的几个参数来计算的,而随机是通过随机数。
哈希算法的选取会严重影响负载均衡的效果,所以要保证该算法计算出来的结果是均匀的,否则就会出现节点负载不均衡的现象。
扩展点
如果节点用来做缓存时,当使用哈希算法来请求数据时,还有另外一个问题,就是 节点发生变化时,会带来大规模的数据迁移。
因为哈希值需要对节点数量取余,所以当节点数量发生变化时,就需要讲数据重新进行运算了,否则按照原来的计算就会拿到错误的数据。
这可以通过 一致性哈希 来很好的解决。
当然了,负载均衡不会存在该问题,因为这里的节点不缓存数据。
一致性哈希
一致性哈希算法引入了 哈希环 的概念,它的取模规则与哈希算法不同,是 对 2^32 进行取模运算,而不是对节点数量进行取模,所以 得到的都是一个固定的值,这些值落到哈希环的各个地方。
一致性哈希算法的 流程 如下:
- 先用某个 key 对 2^32 进行取模运算,得到一个点位;
- 接着 顺时针找到第一个节点(节点的点位提前计算设置好),此 key 就映射到该节点上。
但由于 节点的分布在哈希环上不能保证均匀,所以可能会出现 请求倾斜 的现象。
解决平均问题最简单的办法就是通过增加数量,所以我们可以在哈希环上增加节点的数量,但又不能真的添加节点的数量,毕竟我们没这么多的节点。
一致性哈希算法一般会通过 虚拟节点 来解决,以 提高均衡度,具体来说,可以加多一层映射关系,将大量虚拟节点放在哈希环上,进行哈希映射时,先映射到虚拟节点上,然后再从虚拟节点映射到真实节点,虚拟节点与真实节点是 多对一 的关联,这样即可保证节点在哈希环的相对均匀了。

扩展点
上面提到的当节点数量发生变化时,大规模数据迁移的问题,在一致性哈希算法中也得到了很好的解决。
当节点数量发生变化时,由于 取模运算得到的点位都是固定的,所以此时 只会影响到变化节点的一个下游节点(其他点位还是映射到原来的节点上),从而大大减少了数据迁移的规模。
2.4 最少连接数
最少接连数 需要基于一个假说:如果某个节点上的连接数越多,那么该节点的负载就越高。因此在负载均衡的时候就要 挑选出连接数最少的节点,以获得更好的性能。
该算法的 缺点 在于,连接数并不能正确的反映节点的实际负载,尤其是在多路复用的情况下(一个连接可处理多个请求)。
2.5 最少活跃数
最少活跃数 就是根据节点当前的 活跃请求数量 来反映负载情况,活跃请求是已收到但还没返回的请求。
这个活跃请求数 在客户端维持,每次发送请求时,优先选择活跃请求数少的节点。
与最少连接数类似,活跃请求数也不能正确反映一个节点的实际负载,因为 请求可能是大请求(比如一个请求要处理的数据很多),这样就会出现即使该节点的活跃数少,但实际负载也很高的情况。
2.6 最快响应时间
最快响应时间 用的是 节点的响应时间 来反映负载情况,响应时间跟前两个指标比起来,更加综合、更加准确。
该算法也是 由客户端来维持每个节点的响应时间,优先选举响应时间最短的,说明该节点的性能越高。
在实际使用时,需要注意 响应时间的时效性,一般需要根据最近请求的响应时间来判断,让越近的响应时间,权重越大。也就是 采集响应时间的效用应该随着时间而衰减。
还有另一种思路,根据响应时间自适应的负载均衡算法,能够在大部分情况下保持良好的性能。这个算法也需要在客户端维持一份节点的性能统计快照,每隔一段时间需要更新这个快照。在发起请求时,根据 “二八定律”,把可用节点分为两部分,找出响应最慢的 20% 节点,降低它们的权重(节点权重相差不要太大) 。这样便可以根据节点的响应快慢,来动态调整节点的权重。
2.7 动态负载均衡算法有啥问题
前面讲到的三个动态负载均衡算法都有一个小问题,就是数据都是由客户端维持的,而 不同的客户端数据可能不同。
一个解决办法是 让服务端主动上报,可以有两种思路:
服务端返回响应时顺便把它的一些信息返回(需要微服务框架支持从服务端往客户端回传链路元数据):

服务端定时上报自身信息给观察平台,客户端再查询出来:

不过一般很少使用这么复杂的负载均衡算法,所以大多数微服务框架也不支持服务端上报指标到客户端的机制。
3. 小结
常见的负载均衡算法就介绍完了,在静态负载均衡算法中,加权轮询、一致性哈希使用比较多,因此需要好好掌握,在后面的文章中,我也会详细讲解一致性哈希在更多场景下的使用。
在动态负载均衡算法中,最好使用最快响应时间,因为它能更综合的反映一个节点的实际负载情况。还要注意时效性问题,应当尽量选择近期的响应时间数据。