String 类
本文内容
1. String 基础
String 类表示字符串。Java 程序中的所有字符串字面值,例如 "abc",都被实现为该类的实例,因此字符串属于对象。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence,
Constable, ConstantDesc {
}
可以看见,String 实现了如下类:
java.io.Serializable:可以被序列化;Comparable<String>:支持作比较;CharSequence:描述字符串结构的接口,String、StringBuilder、StringBuffer 都实现了这个类;
1.1 创建字符串的两种方式
有两种方式可以创建字符串,分别是直接通过 "xxx" 和 通过 new String(),例如:
String s = "hello";
String s = new String("hello");
这两种方式是有区别的,因为字符串在 方法区中(JDK 1.6)有一个属于自己的 字符串常量池,是 JVM 为 String 开辟的一块内存缓冲区,好处如下:
- 提高性能 (直接从常量池取字符串);
- 减少内存开销 (避免重复创建字符串)。
以下内容都基于 JDK 1.6 的方法区来讲,后面会详细讲解 JDK 1.8 后的情况。
当创建 String 对象时,JVM 会先检查字符串常量池:
- 若这个字符串的常量值已经存在在池中,就直接返回池中对象的引用;
- 若不在池中,就会实例化一个字符串并放入池中。
如果使用 String s = "hello",那么 只会在字符串常量池中创建一个 "hello" 对象;

如果使用 String s = new String("hello"),那么 除了会先在字符串常量池中创建一个 "hello" 对象外,还会为 new String() 在堆中创建一个 String 对象的实例。
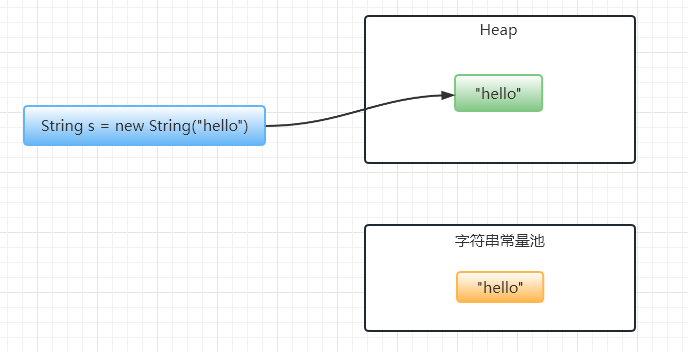
所以,String s = new String("hello") 这句话会 创建一个或者两个对象,取决于字符串常量池中是否含有 "hello"。
1.2 String 常用方法

2. String 的不可变性
2.1 什么是不可变?
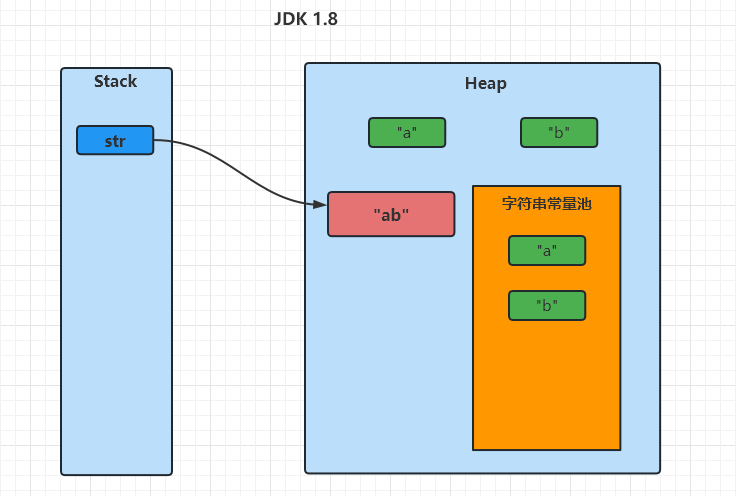
String 不可变很简单,给定一个字符串 String s = new String("hi"),在将这个字符串 s 替换为 "hello",这个操作 不是在原内存地址上替换数据,而是将替换后的字符串重新指向一个新对象、新地址。
如下图(未画字符串常量池):

示例:
System.identityHashCode(Object o) 方法返回对象的哈希码,不管是否重写了 hashCode() 方法。
class Test {
public static void main(String[] args) {
String s = "hi";
System.out.println(System.identityHashCode(s)); // 295530567
s = s.replace("hi", "hello");
System.out.println(System.identityHashCode(s)); // 2003749087
}
}
可以发现,s.replace("hi", "hello") 后,s 的哈希码改变了,说明 s 指向的地址改变了。
其实,任何会改变 String 的方法都会新创建一个 String 变量,将改变后的 String 赋值给这个变量返回,而 不会在原地修改。
下面再使用可变类型的 StringBuilder 来测试:
class Test {
public static void main(String[] args) {
StringBuilder sb = new StringBuilder("hi");
System.out.println(System.identityHashCode(sb)); // 1324119927
sb = sb.append("hello");
System.out.println(System.identityHashCode(sb)); // 1324119927
}
}
可以发现,sb 对象拼接上一个字符串后,还是指向它原来的地址。
2.2 探索 String 不可变的真正原因
首先来看看 final 的作用:
- 被
final关键字修饰的 类不能被继承,修饰的 方法不能被重写; - 修饰 变量 分两种情况(重要):
- 基本类型:值不能改变;
- 引用类型:不能再指向其他对象;
接下来直接翻开 JDK 源码,java.lang.String 类起手前三行是这样的:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence,
Constable, ConstantDesc {
@Stable
private final byte[] value;
// ......
}
从源码中可以得知一下信息:
- String 类用
final修饰,说明 String 类 不可继承; - String 类的主力成员字段
value是一个byte[]数组(JDK 9 之前是char[]),也是用final修饰,被 final 修饰的字段创建后就 不可改变。注意 数组是引用类型,说明value只是不能再指向其他对象;- 注意:是这个
byte[]类型的 变量value不可改变,并不是这个数组不可变。也就是说只是value变量引用的地址不可改变,而 数组本身是可变的;
- 注意:是这个
value变量 只是 stack 上的一个引用,数组的本体结构在 heap 中。String 类里的value用final修饰,只是说 stack 里的这个叫value所引用的地址不可变,没有说 heap 中数组本身中的数据不可变;

举个例子:
final int[] value = {1, 2, 3};
int[] another = {4, 5, 6};
value = another; // 编译报错:不能给 final 变量value 赋值。
因为把 value 重新指向了 another 指向的地址,而 value 用 final 修饰,所以自然是不允许的。
但是如果直接对数组本身进行修改,如下:
final int[] value = {1, 2, 3};
value[2] = 10; // 允许直接对数组本身进行修改
System.out.println(Arrays.toString(value)); // [1, 2, 10]
所以,并不是因为 final 修饰了 String 和 value 就是不可变的了,主要是编写这个类的程序员 把 String 封装得很好,具体体现如下:
- String 被
final修饰,不能被继承,这 避免了其他人继承后破坏; byte[] value被private修饰,只能在本类中对 value 进行操作;- String 类中 没有提供任何能修改
byte[]数组数据的方法;
所以 String 不可变的关键都在底层的实现,而不是单单一个final。
2.3 String 为什么要设计成不可变?
最简单地原因,就是为了 安全。
例如,我们要在某个函数中对字符串进行修改,然后返回新的字符串,如下:
class Test {
public static void main(String[] args) {
String origin = "aaa";
// 不可变的 String 做参数
String updatedStr = updateStr(origin);
System.out.println("origin String: aaa ->" + origin);
StringBuilder originSb = new StringBuilder("aaa");
// 可变的 StringBuilder 做参数
StringBuilder updatedSb = updateSb(originSb);
System.out.println("origin StringBuilder: aaa ->" + originSb);
}
// 不可变的 String
public static String updateStr(String s) {
String newStr = s + "bbb"; // +: 底层使用 StringBuilder 拼接,返回一个新对象
return newStr;
}
// 可变的 StringBuilder
public static StringBuilder updateSb(StringBuilder sb) {
StringBuilder newSb = sb.append("bbb");
return newSb;
}
}
/*
输出:
origin String: aaa ->aaa
origin StringBuilder: aaa ->aaabbb
/*
可以发现:若使用可变的 StringBuilder 做参数,因为 Java 是值传递,引用类型传递的是地址,所以把我们原来的 originSb 的地址传过去,然后进行改变了,但是我们 本意是不想改变它的,只是想把它作为参数进行修改,然后返回一个新的修改后的字符串给我们。
而不可变的 String 做参数的时候,就不会修改掉我们原来的 origin 字符串。
再看下面这个 HashSet 用 StringBuilder 做元素的场景,问题就更严重了,而且更隐蔽。
class Test {
public static void main(String[] args) {
HashSet<StringBuilder> set = new HashSet<>();
StringBuilder sb1 = new StringBuilder("aaa");
StringBuilder sb2 = new StringBuilder("aaabbb");
set.add(sb1);
set.add(sb2);
System.out.println(set); // [aaabbb, aaa]
StringBuilder sb3 = sb1; // 把 sb3 也指向 sb1 的地址
sb3.append("bbb"); // 修改 sb3,其实也修改了 sb1,因为它们指向相同的地址
System.out.println(set); // [aaabbb, aaabbb]
}
}
StringBuilder 型变量 sb1 和 sb2 分别指向了堆内的字面量 "aaa" 和 "aaabbb"。把他们都插入一个HashSet,到这一步没问题。但如果后面不小心 把变量 sb3 也指向 sb1 的地址,再改变 sb3 的值,因为StringBuilder 没有不可变性的保护,sb3 直接在原先 "aaa" 的地址上改,导致 sb1 的值也变了。这时候,HashSet 上就出现了两个相等的键值 "aaabbb”。破坏了 HashSet 键值的唯一性。所以千万不要用可变类型做 HashMap 和 HashSet 键值。
还有一个原因是 String 会保存在字符串常量池中,这样在大量使用字符串的情况下,可以 节省内存空间和提高效率。但之所以能实现这个特性,String 的不可变性是最基本的一个必要条件。要是 内存里字符串内容能改来改去,这么做就完全没有意义了。
此外,String 类中还有一个 hash 变量,如下所示:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
// ......
/** Cache the hash code for the string */
private int hash; // Default to 0
// ......
}
从源码种的注释就能知道,该变量是 给 String 类型变量的 hashcode 值做缓存,这样下次需要获取该 String 变量的 hashcode 值时,就不用再通过哈希运算了。
顺便提一下,像基本数据类型的包装类也是使用 final 修饰的,而且保存值的变量 value 也是使用 final 修饰,所以也是不可变类。因为 Java 也为包装类型提供了缓存,例如 Integer 的缓存范围在 -128 至 127 之间,因为这个范围的数字是经常使用的。
不过需要注意的是,该缓存只适用于自动装箱时使用,当用构造函数时,不会使用缓存。
Integer i1 = 10; Integer i2 = 10; System.out.println(i1 == i2); // true(i2 直接指向缓存的数据) Integer i1 = 1000; Integer i2 = 1000; System.out.println(i1 == i2); // false(超过了缓存范围) Integer i1 = new Integer(10); Integer i2 = new Integer(10); System.out.println(i1 == i2); // false(只有自动装箱时才会用到缓存)
3. String 常见问题
3.1 String、StringBuffer、StringBuilder 的区别
从可变性来说:
String是不可变的,它被final和private修饰;StringBuilder与StringBuffer都继承自AbstractStringBuilder类,在AbstractStringBuilder中也是使用 byte 数组保存字符串,不过没有使用final和private关键字修饰,最关键的是这个AbstractStringBuilder类还提供了很多修改字符串的方法 比如append方法。abstract class AbstractStringBuilder implements Appendable, CharSequence { byte[] value; public AbstractStringBuilder append(String str) { if (str == null) return appendNull(); int len = str.length(); ensureCapacityInternal(count + len); str.getChars(0, len, value, count); count += len; return this; } //... }
从线程安全性来说:
String中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder是StringBuilder与StringBuffer的公共父类,定义了一些字符串的基本操作,如expandCapacity、append、insert、indexOf等公共方法。StringBuffer对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder并没有对方法进行加同步锁,所以是非线程安全的。
从使用性能来说:
- 每次对
String类型进行改变的时候,都会生成一个新的String对象,然后将指针指向新的String对象。在修改较多的场景性能不太好。 StringBuffer每次都会对StringBuffer对象本身进行操作,而不是生成新的对象并改变对象引用。- 相同情况下使用
StringBuilder相比使用StringBuffer仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者的使用总结:
- 操作少量的数据适用
String; - 单线程操作字符串缓冲区下操作大量数据适用
StringBuilder; - 多线程操作字符串缓冲区下操作大量数据适用
StringBuffer;
3.2 字符串拼接用 "+" 还是 StringBuilder?
Java 语言本身并不支持运算符重载,“+” 和 “+=” 是专门为 String 类重载过的运算符,也是 Java 中仅有的两个重载过的运算符。
String str1 = "he";
String str2 = "llo";
String str3 = "world";
String str4 = str1 + str2 + str3;
上面的代码对应的字节码如下:

可以看出,字符串变量通过 “+” 的字符串拼接方式,实际上是 通过 StringBuilder 调用 append() 方法实现的,拼接完成之后调用 toString() 得到一个新的 String 对象。
注意:在循环内使用 “+” 进行字符串的拼接的话,存在比较明显的缺陷:编译器不会创建单个 StringBuilder 以复用,会导致创建过多的 StringBuilder 对象。
String[] arr = {"he", "llo", "world"};
String s = "";
for (int i = 0; i < arr.length; i++) {
s += arr[i];
}
System.out.println(s);
StringBuilder 对象是在循环内部被创建的,这意味着 每循环一次就会创建一个 StringBuilder 对象,所以效率是很低的。
如果直接使用 StringBuilder 对象进行字符串拼接的话,就不会存在这个问题了。
String[] arr = {"he", "llo", "world"};
StringBuilder s = new StringBuilder();
for (String value : arr) {
s.append(value);
}
System.out.println(s);

3.3 String 类型的变量和常量做 "+" 运算时发生了什么?
先来看字符串不加 final 关键字拼接的情况(JDK1.8):
String str1 = "str";
String str2 = "ing";
String str3 = "str" + "ing"; // 常量做 +
String str4 = str1 + str2; // 变量做 +
String str5 = "string";
System.out.println(str3 == str4); //false
System.out.println(str3 == str5); //true
System.out.println(str4 == str5); //false
对于 编译期可以确定值的字符串,也就是 常量字符串 ,JVM 会将其 存入字符串常量池。并且,字符串常量 拼接得到的字符串常量在编译阶段就已经被存放字符串常量池,这个得益于编译器的优化。
对于 String str3 = "str" + "ing"; 编译器会优化成 String str3 = "string"; 。
而字符串类型的变量通过 “+” 的字符串拼接方式,实际上是 通过 StringBuilder 调用 append() 方法实现的,拼接完成之后调用 toString() 得到一个新的 String 对象。
不过,字符串使用 final 关键字声明之后,可以让编译器当做常量来处理:
final String str1 = "str";
final String str2 = "ing";
// 下面两个表达式其实是等价的
String c = "str" + "ing"; // 常量池中的对象
String d = str1 + str2; // 常量池中的对象
System.out.println(c == d); // true
被 final 关键字修改之后的 String 会被编译器当做常量来处理,编译器在程序编译期就可以确定它的值,其效果就相当于访问常量。
3.4 JDK 9 为什么要把 char[] 改为 byte[]?
在 Java 9 之后,String 、StringBuilder 与 StringBuffer 的实现改用 byte 数组存储字符串。
新版的 String 其实支持两个编码方案: Latin-1 和 UTF-16。
如果字符串中包含的字符没有超过 Latin-1 可表示范围内的字符,那就会使用 Latin-1 作为编码方案。
Latin-1 编码方案下,byte 占 1 个字节,char 占用 2 个字节,byte 相较 char 节省一半的内存空间。
如果字符串中包含的字符超过 Latin-1 可表示范围内的字符,byte 和 char 所占用的空间是一样的。
4. JDK 8 方法区的更变
4.1 永久代与元空间
在 JDK 1.6 的 HotSpot 中,把方法区称为 永久代,本质上两者并不等价,仅仅是因为 HotSpot 虚拟机的设计团队选择把 GC 分代收集至方法区,或者说用永久代来实现方法区而已。这样 HotSpot 的垃圾收集器可以像管理 Java 堆一样管理这部分内存,能省去专门为方法区编写内存管理代码的工作。
JDK 8 开始,使用 元空间 取代了永久代。元空间本质和永久代类似,都是对 JVM 规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。

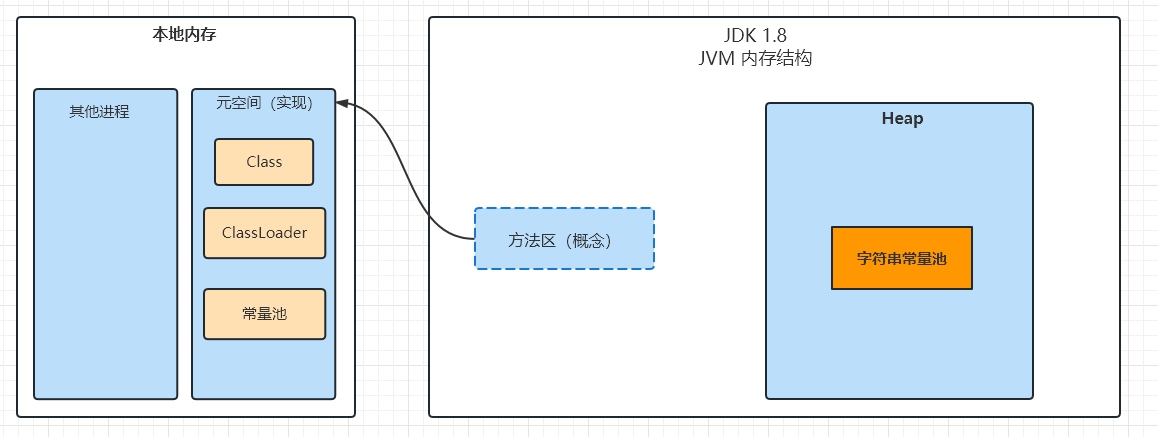
4.2 字符串延迟加载
字符串对象的创建都是 懒惰的,执行到的时候才会加载,不是一次性加载完。
只有当运行到那一行字符串且在串池中不存在的时候时,该字符串才会被创建并放入串池中。
利用 IDEA 中的 Memory(查看运行时类对象个数)验证:
public static void main(String[] args) throws InterruptedException {
System.out.println(); // java.lang.String 2093
System.out.println("1"); // java.lang.String 2094
System.out.println("2");
System.out.println("3");
System.out.println("4");
System.out.println("5");
System.out.println("6");
System.out.println("7");
System.out.println("8");
System.out.println("9");
System.out.println("0"); // java.lang.String 2103
// 以下的字符串与上面重复,直接从字符串池中获取,String对象的数量不会增加
System.out.println("1"); // java.lang.String 2103
System.out.println("2"); // java.lang.String 2103
System.out.println("3");
System.out.println("4");
System.out.println("5");
System.out.println("6");
System.out.println("7");
System.out.println("8");
System.out.println("9");
System.out.println("0");
}
4.3 intern() 方法
字符串常量池主要用于存储在 编译期 生成的字符串对象,而如果 想要在运行期将字符串对象加入到串池中,则可以使用 intern() 方法。
调用字符串对象的 intern() 方法,主动 将字符串对象放入到串池中:
- JDK1.8:将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则将该字符串放入串池, 最后把串池中的对象的引用返回;
- JDK1.6:将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把 此对象复制一份, 将复制的新对象放入串池, 原来的对象还是在堆中,最后把串池中的对象返回;
可以发现在 JDK 1.8 和 JDK 1.6 中,无论字符串放入串池是否成功,最后都会返回串池中的对象。
下面分别在 JDK 1.8 和 JDK 1.6 环境中来举例子,彻底搞懂 intern() 方法。
JDK 1.8 环境
在 JDK 1.8 环境下:
- 如果调用
intern()方法成功,堆内存与串池中的字符串对象是同一个对象,毕竟串池也在堆内存中; - 如果失败,则 不是同一个对象。
示例 1:
注意:"a" + "b" 会在编译时优化 ,而 new String("a") + new String("b"); 不会,它相等于使用 StringBuilder 的 append() 方法拼接,然后再返回一个新字符串对象 "ab"。
public class Main {
public static void main(String[] args) {
// "a"和"b" 被放入串池中,str 则存在于堆内存之中
String str = new String("a") + new String("b");
// 此时串池中没有 "ab" ,则会将该字符串对象放入到串池中,此时堆内存与串池中的 "ab" 是同一个对象
String str2 = str.intern();
// 给 str3 赋值,因为此时串池中已有 "ab" ,则直接将串池中的内容返回
String str3 = "ab";
// 堆内存与串池中的 "ab" 是同一个对象
System.out.println(str == str2); // true
System.out.println(str2 == str3); // true
}
}
调用 intern() 前:
调用 intern() 后:

示例 2,将 str3 放在前面:
public class Main {
public static void main(String[] args) {
// 此处创建字符串对象 "ab" ,因为串池中还没有 "ab" ,所以将其放入串池中
String str3 = "ab";
// "a" 和 "b" 被放入串池中,str 则存在于堆内存之中
String str = new String("a") + new String("b");
// 此时"ab" 已存在与串池中,所以放入失败,str 还是堆中的"ab",但是会返回串池中的 "ab"
String str2 = str.intern();
System.out.println(str == str2); // false,堆中的str没有放入串池中,而str2是从串池的返回的
System.out.println(str2 == str3); // true
}
}
调用 intern() 前:

调用 intern() 后:

JDK 1.6 环境
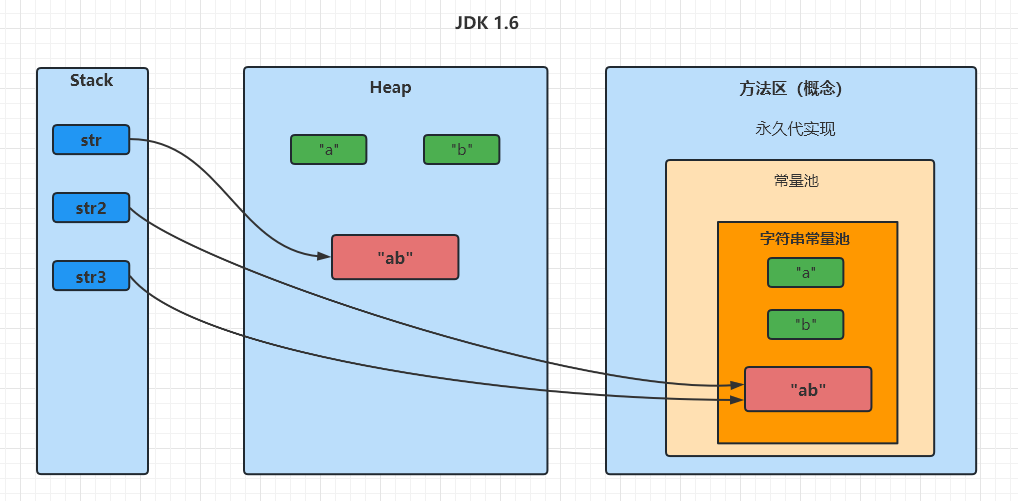
在 JDK 1.6 环境下,此时无论调用 intern() 方法成功与否,串池中的字符串对象和堆内存中的字符串对象 都不是同一个对象,因为串池在方法区,不在堆区内。
示例 1,和 JDK1.8 情况 不同:
public class Main {
public static void main(String[] args) {
// "a"和"b" 被放入串池中,str 则存在于堆内存之中
String str = new String("a") + new String("b");
// 此时串池中没有 "ab" ,JDK1.6 则会将该字符串复制一份,将复制的新对象放入到串池中,
// str 本身还只是在堆中,最后也会返回串池中的 "ab" 对象,所以 str2 在串池中
String str2 = str.intern();
// 给 str3 赋值,因为此时串池中已有 "ab" ,则直接将串池中的内容返回
String str3 = "ab";
// str 不在串池中
System.out.println(str == st2); // flase
System.out.println(str2 == str3); // true
}
}
调用 intern() 前:

调用 intern() 后:
示例 2,将 str3 放在前面,和 JDK1.8 情况相同:
public class Main {
public static void main(String[] args) {
// 此处创建字符串对象 "ab" ,因为串池中还没有 "ab" ,所以将其放入串池中
String str3 = "ab";
// "a" 和 "b" 被放入串池中,str 则存在于堆内存之中
String str = new String("a") + new String("b");
// 此时 "ab" 已存在与串池中,所以放入失败,str 还是堆中的"ab",但是会返回串池中的 "ab"
String str2 = str.intern();
System.out.println(str == str2); // false,堆中的 str 没有放入串池中,而 str2 是从串池的返回的
System.out.println(str2 == str3); // true
}
}
调用 intern() 前:

调用 intern() 后:

intern() 使用场景
我们就使用 JDK 1.8 来讲解了,intern() 有两个作用:
- 将字符串对象放入串池(若没有);
- 返回对象在串池中的引用。
我们知道,在编译期就能确定的字符串,则会添加进串池中,但是如果需要在运行期添加,则需要使用 intern()。所以就意味着不能乱使用该方法。
例如,像 String s = new String("hello").intern(); 这样使用该方法时,其实 intern() 是多余的,因为在编译期字符串 hello 就已经确定好了,因此会被加入到串池中,无需 intern() 方法将其放入。
再比如,像 String s = "hello" + "world";,由于编译期的优化,会将此优化为字符串 helloworld,所以串池中只会存在 helloworld,而不存在 hello 和 world。
再比如:
String s1 = "hello";
String s2 = "world";
String s3 = s1 + s2;
- 此时就不存在优化了,
hello和world存在串池中,而helloworld不存在。所以在有需要时得使用intern()方法将其放入串池。
通过上面的例子,可以得出 intern() 的使用场景主要是 得到的字符串在编译期间无法确定,而是在运行期间才能确定的,则需要使用 intern() 方法将其放入串池中。
比如下面的例子,我们需要创建 MAX 个字符串,存入 arr 数组中:
static final int MAX = 1000 * 10000;
static final String[] arr = new String[MAX];
public static void main(String[] args) throws Exception {
Integer[] DB_DATA = new Integer[10];
Random random = new Random(10 * 10000);
for (int i = 0; i < DB_DATA.length; i++) {
DB_DATA[i] = random.nextInt();
}
long t = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
//arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length]));
arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length])).intern();
}
System.out.println((System.currentTimeMillis() - t) + "ms");
System.gc();
}
我们使用一个长度为 10 的数组 DB_DATA 来为字符串数组 arr 填充数据,所以其实不同的字符串就 10 个,但是字符串数组长度有 10000000:
- 不使用
intern()时,由于这些字符串都是 在运行时才能确定的,所以会生成 1000w 个字符串; - 使用
intern()后,前 10 此循环就会把这十个字符串都放入串池,后续的字符串都是直接引用串池中的即可,因此就生成了 10 个字符串。
因此,使用 intern() 节约了非常大的空间,不过消耗的时间也会稍微长一点,因为每次都是用了 new String 后,然后又进行 intern() 操作的消耗时间。但是相比于节约出来的大量空间,这点耗时也是不亏的。