分布式选举:国不可一日无君
本文内容
前言
谈到分布式,那必定涉及到集群了,因为分布式无非就是加几台机器,那么这一群机器就组成了一个集群。集群中的各台机器,也叫作节点。
那集群中的节点都是怎么协同、怎么管理的呢?这就需要一个 Leader 来负责调度和管理其他节点,以达到集群中的数据一致性。
在分布式中,这个 Leader 被称为 主节点,而选举 Leader 的过程,就叫作 分布式选举。
1. 为什么要有分布式选举?
在分布式中,主节点负责调度、管理和协调其他节点,在主节点的管理下,能保证集群正确有序的运行。
试想一下,如果主节点一旦故障,其他节点应该如何应对?就好比皇上驾崩,天下大乱一样。这就像 “国不可一日无君”,在分布式中称为 “集群不可一刻无主”。
所以就需要有一个机制,在主节点故障后,能在其他节点中选举出一个新的主节点,以保证集群能正常的运行,这个过程就是 分布式选举。
目前常见的分布式选举方法有:
- 基于序号选举的算法:Bully 算法;
- 多数派算法:Raft 算法、ZAB 算法。
2. Bully 算法:长者为大
2.1 基本概念
Bully 算法是一种以 “长者” 为大的集群选主算法,即在所有活着的节点中,选择 ID 最大的作为主节点。
Bully('bʊli),翻译为横行霸道、仗势欺人。
在 Bully 算法中,需要使用 3 种消息:
- Election 消息:用于发起选举;
- Alive 消息:对 Election 消息的应答;
- Victory 消息:向其他节点发送宣誓主权的消息。
由于 Bully 算法的选举原则是 ID 最大,因此集群中的 每个节点都要知道其他节点的 ID。
当主节点故障或与其他节点失去联系后,或者有更大 ID 的节点加入集群,才会重新选主。节点会定期向主节点发送 心跳消息 来检测它是否在线,若一段时间后没有收到主节点的回复,则认为该主节点已经故障,则会发起选举。
2.2 选举过程
一次 Bully 算法选举的过程如下:
- 每个节点判断自己 ID 是否为集群中的最大值:
- 如果是则向其他节点发送 Victory 消息宣誓主权;
- 如果不是则向比自己大的节点发送 Election 消息;
- 若节点收到比自己 ID 小的 Election 消息,则回复 Alive 消息,告诉它我比你大,你不可能成为主节点;
- 在给定时间范围内:
- 节点没有收到 Alive 消息,则认为自己成为主节点,并向其他节点发送 Victory 消息宣誓主权;
- 若收到比自己 ID 大的 Alive 消息,则等待其他节点发送 Victory 消息。
举个例子,假设原来集群的主节点是 4,现在出现了故障,其他节点通过心跳检测发现主节点已经故障,触发了选举,则 Bully 算法的选举过程如下:
由于其他节点的 ID 都不是集群中最大的,所以他们都会发送 Election 消息:
节点 4 虽然是主节点,但它已经故障了,自然也发不出 Victory 消息。
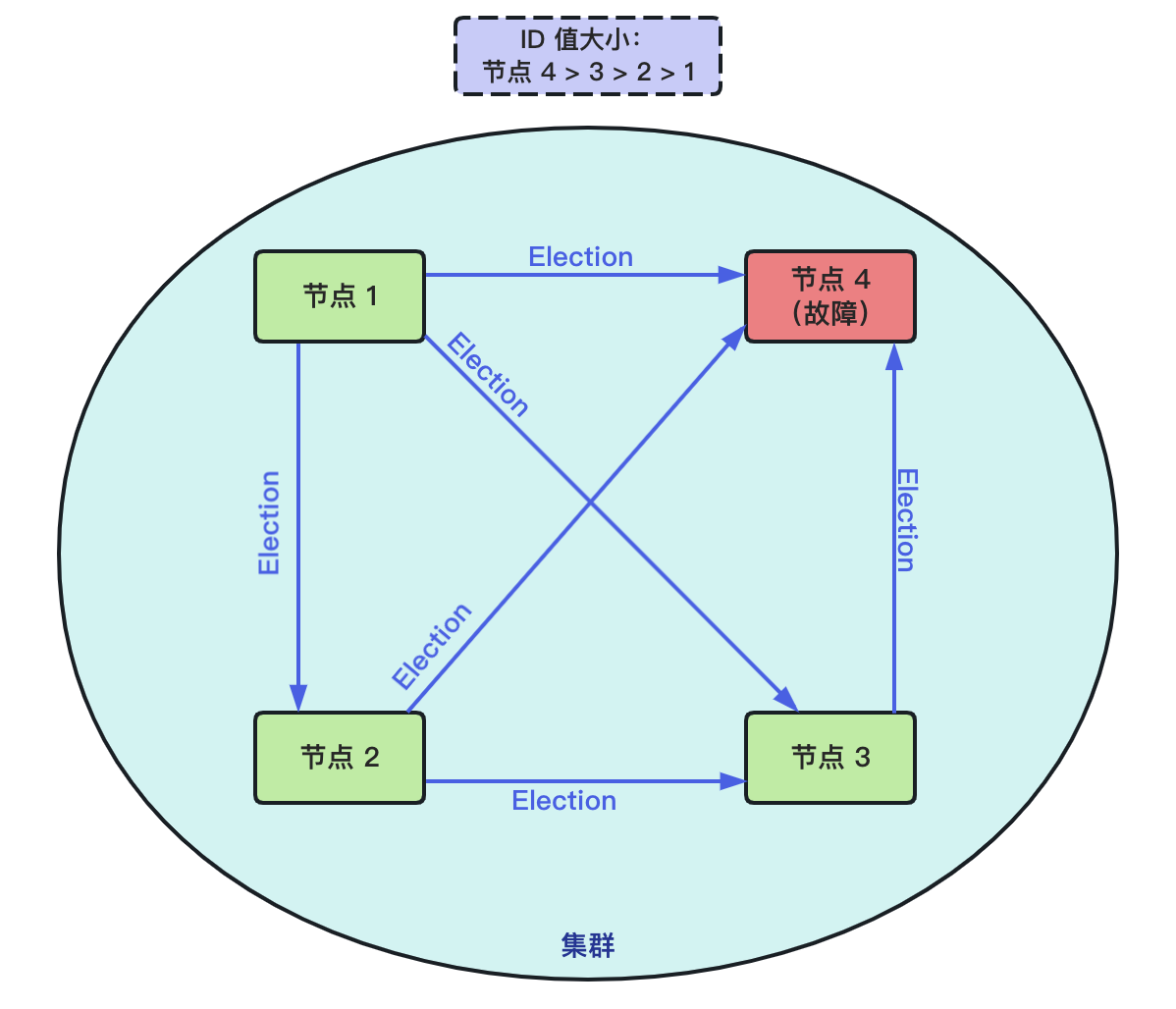
各节点收到 Election 消息后,向比自己 ID 小的发出 Alive 消息:

一段时间后,节点 3 发生没有收到 Alive 消息,则向其他节点发送 Victory 宣誓主权,自己成为主节点:

2.3 Bully 优缺点
优点:
- 选举简单、速度快:由于确定了选主的唯一性(ID 最大者)
缺点:
额外存储:每个节点需要保存其他节点的 ID 信息;
主节点假死:若主节点负载过高,无法对其他节点及时做出响应,就是出现假死现象。这会导致重新选举后,原来的主节点又恢复了,则又要进行一轮选举;
脑裂问题:脑裂问题是由于网络问题而造成一个集群中出现了两个或以上的主节点,进而导致整个集群的数据出现不一致。
假设选举过程中,ID 最大的节点给 ID 第二大的节点发送的 Alive 消息由于网络问题丢失了,那么 ID 第二大的节点也会认为自己是主节点,这就导致了一个集群中有两个主节点。
解决方案
主节点假死的解决:
- 让集群中一半以上的节点都认为主节点故障了,才开始新的选举。
脑裂问题的解决:
- 向比自己 ID 大的节点发送 Election 消息后,如果没有收到对应的 Alive 回复,则发送一次 探活消息,以确保比自己 ID 大的节点是否真的已经故障了。
3. Raft 算法:民主投票
3.1 基本概念
Raft 算法 的核心思想是 通过投票选举,最后以少数服从多数来确定主节点。就跟我们平时进行民主投票选举什么书记一样。
在 Raft 算法中,集群节点有 3 种角色:
- Leader:主节点,负责协调和管理其他节点;
- Candidate:候选者,每个节点都可成为 Candidate,Candidate 有机会被选为新的 Leader;
- Follower:Leader 的跟随者,不可发起选举。
在 Raft 算法中,选举后的 Leader 节点是有任期的,到了后就需要重新选举。当然了,如果 Leader 节点故障,则会马上发起选举。
3.2 选举过程
Raft 选举分为下面几步:
- 初始化时,所有节点均为 Follower 状态;
- 开始选主时,所有节点变为 Candidate 状态,并向其他节点发起选举请求;
- 其他节点按照收到请求的先后顺序,回复是否同意其成为主。注意:每一轮的选举中,一个节点只能投一次票。
- 若发起选举请求的节点获得超过一半的投票,则可成为主节点。
- 此时该节点的状态变为 Leader,其他节点则由 Candidate 降为 Follower;
- Leader 节点与 Follower 节点会定期发送心跳包来检测存活状态。
- Leader 节点任期(term)到后,状态降为 Follower,开始进入新一轮的选主。
可以发现,Raft 算法在正常工作期间只有 Leader 和 Followers,Candidate 只有在选举时才出现。
Raft 算法将时间分为一段一段的任期(term),每段 term 的开始都是选举,然后以选举是否成功来觉得该 term 是否继续:
- 若选举失败,则该 term 直接结束,开启一下段 term;
- 若选举成功,则集群正常运行,直到下一个任期的到来。

在选举过程中,各个状态的转变如下:

3.3 Raft 优缺点
优点:
- 选举速度快、实现复杂度低;
- 稳定性比 Bully 好,因为只有在票数过半时才会切主,不会因为主节点假死而导致频繁切主。
缺点:
- 节点间通信量大:每个节点都要互相通信,且需要票数过半才能选主成功。
4. ZAB 算法:具备优先级的民主投票
4.1 基本概念
ZAB(Zookeeper Atomic Broadcast,Zookeeper 原子广播)选举算法是为 Zookeeper 实现分布式协调而设计的,用于保证 Zookeeper 在分布式环境下的一致性和可靠性。
相比于 Raft 的投票机制,ZAB 添加了节点 ID 和数据 ID 作为参考进行选主。节点 ID 和数据 ID 越大,说明数据越新,越优先成为主。
- 节点 ID 用来标识节点的顺序,单调递增,ID 越大表示加入集群的事件越晚;
- 数据 ID 用来标识数据的写操作顺序,每个写操作都会将数据 ID +1,ID 越大表示数据越新。
在 ZAB 算法选举时,集群节点有 3 种角色:
- Leader:主节点;
- Follower:跟随者节点;
- Observer:观察者节点,无投票权。
在选举过程中,节点拥有 4 种状态:
- Looking 状态:选举状态,节点处于 Looking 时,它会认为集群中没有 Leader,因此自己进入选举状态;
- Leading 状态:领导者状态,表示已经选出主,当前节点为 Leader;
- Following 状态:跟随者状态,选出主后,其他非主节点状态就为 Following 状态;
- Observing 状态:观察者状态,表示节点持观望态度,没有投票和选举权。
投票过程中,每个节点都有一个唯一的三元组:
- server_id:节点的唯一 ID;
- server_zxID:节点存放的数据 ID,数据 ID 越大数据越新;
- epoch:当前选举轮数,一般用逻辑时钟表示。
ZAB 选举算法的核心是 “少数服从多数,ID 大的节点优先”,选举时通过 (vote_id、vote_zxID) 来表明投票给哪个节点。
- vote_id:被投票节点的 ID;
- vote_zxID:被投票节点的服务器 zxID。
ZAB 选主原则:server_zxID 最大者成为 Leader,若 server_zxID 相同,则 server_id 最大者成为 Leader。
4.2 选举过程
以 3 个 Server(节点)的集群为例,下面来看看 ZAB 算法的选主过程:
系统启动时,3 个服务器都是第一轮投票(epoch=1),且无操作数据(zxID=0),此时每台服务器都推选自己成为主。将投票信息 <epoch, vote_id, vote_zxID> 广播出去:
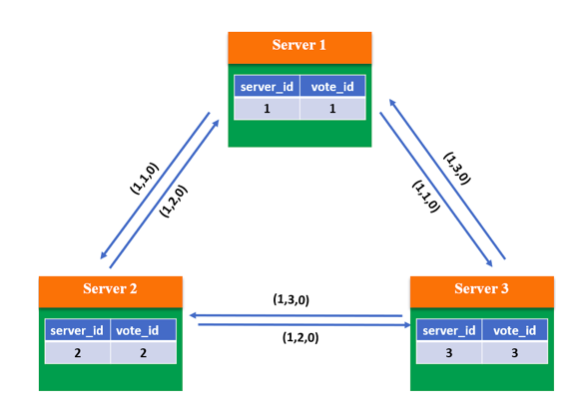
根据选主规则,由于 3 个服务器的 epoch、zxID 都相同,因此将 server_id 较大者推选为主。所以 Server 1 和 Server 2 将 vote_id 改为 3,然后重新广播:
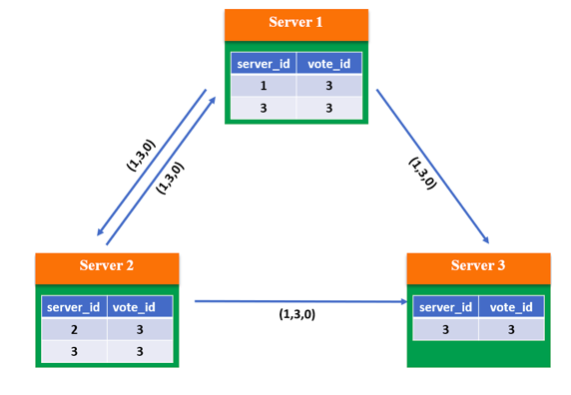
所有服务器都推选了 Server 3,票数过半,因此它成为 Leader,处于 Leading 状态。此时向其他服务器发送心跳包并维护连接,然后 Server 1 和 2 处于 Following 状态:
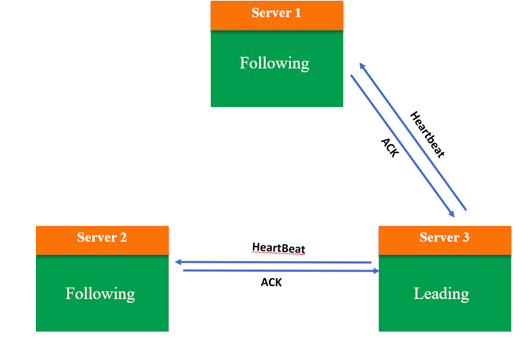
这样这一轮的选举就完成了。
4.3 ZAB 的优缺点
优点:
- 稳定性好,选主时得票数过半,且节点数据 ID(server_zxID)和节点 ID(server_id)较大者,才会切主;
缺点:
- 采用广播发送信息,若集群中信息量较大时,容易引发广播风暴;
- 选举时间较长:除了投票外,还要一一对比节点 ID 和数据 ID。
5. 总结
在讲解了分布式选举的 3 种经典算法 Bully、Raft、ZAB 后,下面从消息传递内容、选举机制和选举过程,对它们进行一个简单的对比:

注:性能是根据算法的选举延迟、正确性、稳定性等特性来综合考量的。
LastTip
对于 “少数服从多数” 的选举算法而言,一般集群中的节点数量会是奇数个,是为了避免选举过程中出现平票而重新进行多次选举。