HTTP 入门
本文内容
1. HTTP 是什么
HTTP 全称是 Hyper Text Transfer Protocol,意为超文本传输协议。它是 应用层 一个简单的 请求-响应 协议,通常运行在 TCP 之上(HTTP 3.0 之前)。
超文本传输协议可以拆分成以下三个部分:
- 超文本:HTTP 传输的内容是「超文本」。常见的超文本就是 HTML(超文本标记语言),其中很多标签定义了图片、视频等链接;
- 传输:HTTP 是基于 B/S 模式,用于浏览器—服务器 两端之间的数据传输;
- 协议:HTTP 是一种 网络协议,它有一套自己的 约定和规范。
所以,可以使用一句话来总结 HTTP:
- HTTP 是网络世界中在「两端」之间「传输」文字、图片、视频等「超文本」数据的「约定和规范」。
2. HTTP 发展历程
2.1 HTTP/0.9 — 单行协议
HTTP 0.9 是 HTTP 协议的第一个版本,及其简单,其特点如下:
请求由单行指令构成,请求方法 只有 GET,后面跟目标资源的路径,如下:
GET /home.html只能响应 文本 内容,不过也支持 HTML 标签,如下:
<HTML> this is a simple page </HTML>没有请求/响应头和状态码;
2.2 HTTP/1.0 — 可扩展性
由于 HTTP/0.9 协议的局限性,所以迅速扩展其功能,构建了 HTTP/1.0 版本,其特点如下:
- 支持三种请求方法:GET、POST、HEAD。HEAD 方法和 GET 一样,只是不返回响应主体,只有响应头,常用于确认 URL 的有效性;
- 引入 HTTP 头 的概念,请求和响应都有对应的头部消息;
- 可传输除文本外的其他 超链接,如图片、视频、链接等,使用
Content-Type头标识; - 引入 状态码,可以方便知道请求的状态是成功还是失败;
现在一个经典的请求—响应的内容如下:
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<HTML>
一个包含图片的页面
<IMG SRC="/myimage.gif">
</HTML>
接下来第二个连接请求获取图片:
GET /myimage.gif HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:32 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/gif
(这里是图片内容)
但是 HTTP/1.0 也有很大的 缺点:
- 短连接:一次请求—响应对应一次连接,下次请求又要重新建立连接;
- 队头阻塞:一个请求一个响应的应答方式,前一个请求的响应未到达则不能再次发送请求;
2.3 HTTP/1.1 — 标准化
HTTP/1.1 在 HTTP/1.0 的基础上,进行了许多改进,其特点如下:
- 默认使用 长连接(Connection 头部标识),使得连接可以复用,节省了多次连接的时间;
- 支持 管道网络传输,允许在前一个请求未响应之前就发送第二个请求;
- 注:解决了请求的队头阻塞,但是 未解决响应的队头阻塞;
- 引入 内容协商机制,包括语言、编码、类型等,在 HTTP 请求头中指定;
- 凭借 Host 头部,能够使不同域名配置在同一个 IP 地址的服务器上;
一个典型的请求—响应流程,所有请求都通过一个连接实现,看起来就像这样:
GET /en-US/docs/Glossary/Simple_header HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
200 OK
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Wed, 20 Jul 2016 10:55:30 GMT
Etag: "547fa7e369ef56031dd3bff2ace9fc0832eb251a"
Keep-Alive: timeout=5, max=1000
Last-Modified: Tue, 19 Jul 2016 00:59:33 GMT
Server: Apache
Transfer-Encoding: chunked
Vary: Cookie, Accept-Encoding
(content)
在同一个连接中,继续请求静态资源:
GET /static/img/header-background.png HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
200 OK
Age: 9578461
Cache-Control: public, max-age=315360000
Connection: keep-alive
Content-Length: 3077
Content-Type: image/png
Date: Thu, 31 Mar 2016 13:34:46 GMT
Last-Modified: Wed, 21 Oct 2015 18:27:50 GMT
Server: Apache
(image content of 3077 bytes)
但是 HTTP/1.1 也有一些 缺点:
- 请求/响应头部未经压缩就发送,而且就算每次请求的头部相同,也会 发送冗长首部;
- 虽然请求支持管道传输,但是 服务器响应还是按照请求的顺序响应,所以存在 响应的队头阻塞;
- 请求只能从客户端开始,服务器不能主动推送消息;
- 明文传输,数据不安全,存在被 窃听、篡改、冒充 的风险;
2.4 HTTP/2.0 — 表现优异
HTTP/2.0 解决了 HTTP/1.1 的缺点,可以说是一个非常优异的版本了。其改进的点如下:
- 头部压缩:会压缩头部信息,如果发出多个请求头部都是相似的,协议会消除重复的部分;
- Stream 数据流:每个请求或响应的所有数据包,称为一个数据流,数据流的帧可以乱序发送,通过 Stream ID 来组装成一条 HTTP 消息;
- 多路复用:可以在一个 TCP 连接中并发多个 HTTP 请求或响应,不需要按顺序一一对应;
- 解决了 响应的队头阻塞,可以优先响应处理好的请求;
- 服务器可以主动推送消息;
- 二进制格式:请求头和数据体都是二进制,无需进行报文到二进制的转换,增加了数据的传输效率;
- 基于 HTTPS:安全性得到了保障;

HTTP/2.0 是现在使用的最广泛的版本。
但其实 HTTP/2.0 并 没有完全解决队头阻塞 问题,因为 HTTP 是基于 TCP 的,而 TCP 是安全可靠的协议,所以 队头阻塞问题存在 TCP 这层:
- 在发生报文丢失时,TCP 层没有收到完整连续的数据,则内核缓冲区中已到达的数据也不能返回给 HTTP 层,等丢失的数据到达后,HTTP 层才能从内核缓冲区中获取数据;
- 而且,如果接收方没有及时回复 ACK,那么发送方的滑动窗口也不能继续向前滑动,因此发送方也会阻塞。
所以一旦发生了 丢包 现象,就会触发 TCP 的 重传机制,这样在一个 TCP 连接中的 所有的 HTTP 请求都必须等待这个丢了的包被重传回来。
2.5 HTTP/3.0 — 强势来袭
为了解决 HTTP/2.0 TCP 层的队头阻塞问题,HTTP/3.0 直接抛弃 TCP,采用了 UDP。UDP 发送是不管顺序和丢包的,所以不会出现像 HTTP/2.0 的队头阻塞问题。
为了保证数据的可靠性,HTTP/3.0 引入了 QUIC 协议,它具有如下特点:
- 无队头阻塞;
- 更快的连接建立;
- 连接迁移;
但是 HTTP/3.0 引入的 QUIC 协议比较新颖,因此很多网络设备其实识别不出来,只会将它当作 UDP 协议来处理,所以现在还并不适用,但未来可期 ~
3. URI 和 URL
3.1 URI 是什么
URI 全称 Uniform Resource Identifier,意为统一资源 标志符,标识了网络中的某个对象或者集合。
注意这里的「标志符」,下面在讲 URL 时会提到。
URI 可以是 Web 系统中的某个图片地址,也可以是某个人的邮箱地址等等。
URI 的格式
下面的 scheme 指的是协议,URI 的通用格式没有太多限制,一般是以 scheme 开头,冒号 ":" 分隔开:
<scheme>:<scheme-specific-part>
虽然 URI 的格式没有怎么限制,但是不同 scheme 一般会遵循下面的格式来定义:
<scheme>://<authority><path>?<query>
以 scheme = http 为例,scheme 格式如下:
http://www.google.com:80/search?q=什么是URI
http 的 <authority> 一般不会写在路径上,所以上面的 scheme 格式解析如下:
<scheme>为 http;<path>为 www.google.com:80/search;<query>为 q=什么是URI;
是不是发现,这就是我们通常在地址栏填写的地址,只不过现在大多都是使用 https。
下面再列举一些其他的 RUI 用法:
ftp://192.168.10.1/baidu/baidu123.txt;telnet://myhome.me/0;
所以 scheme(协议)有很多,http 只是其中的一种协议。
3.2 URL
前面我们知道了 URI 是网络中用于标识某个对象的规约,URI 包含了多个 <scheme>,所以 URL 是 scheme = http 的 URI。
URL 和 URI 只差了一个字母,Location 和 Identifier:
- Location:定位,着重强调的是 位置信息;
- Identifier:标识符,只是一种 全局唯一的昵称。
URI 就好比告诉了你某个东西表示的是什么,而 RUL 则是具体的告诉你这个东西的具体地址在哪儿。
例如,中国就是一个标识符,它表示一个国家,但是只通过这个标识符,你能知道这个国家在哪儿吗?
而如果把定位告诉你,比如中国的经纬度位置,这就是定位,你就知道中国所处的位置信息。
4. HTTP 报文格式
HTTP 报文分为请求报文和响应报文,它们的报文格式有些许不一样,下面分别来看看。
4.1 HTTP 请求报文格式
HTTP 请求报文由三部分组成,分别是 请求行、请求头和请求体:

- 请求行:包含请求方法、请求资源文件的 URL 地址(不含域名)、使用的协议和版本号;
- 请求头:包含若干属性,格式为
属性名:属性值,常见的属性包括接收的数据格式/编码/语言、目标服务器的域名、缓存控制、Cookie 等。 - 请求体:请求的内容。
示例:

4.2 HTTP 响应报文格式
HTTP 请求报文也是由三部分组成,分别是 响应行、响应头和响应体:
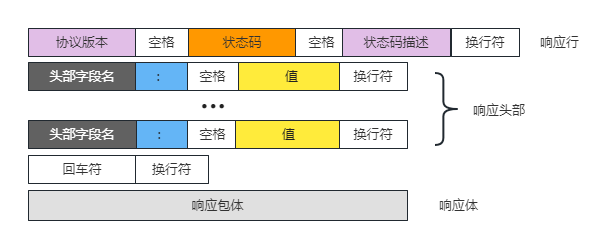
- 响应行:使用的协议和版本号、状态码、状态码的描述信息;
- 响应头:包含若干属性,格式为
属性名:属性值,常见的属性包括响应的数据格式/编码、响应的数据长度等; - 响应体:响应的内容。
示例:

4.3 请求/响应头常见字段
Host 字段
客户端发送请求时,Host 用来指定服务器的域名,能够使 不同域名配置在同一个 IP 地址的服务器上。
因此,可以将请求发往 同一个 IP 地址服务器的不同网站:

Connection 字段
Connection 字段主要用于客户端要求服务器使用长连接,以便其他请求复用。
HTTP/1.1 版本的默认连接都是持久连接,但为了兼容老版本的 HTTP,需要指定 Connection 首部字段的值为 Keep-Alive。
如下:

Content-Type 字段
Content-Type 用于表示 响应报文的数据格式,如下表示返回的是一个网页,编码为 utf-8:

客户端在请求时,可以通过 Accept 字段声明自己可以接受的数据格式,如下:

Content-Length
Content-Length 字段表示 响应数据的长度,使用此字段可以告诉浏览器本次响应的数据长度,剩下的数据是下一个响应了。
如下:

Content-Encoding 字段
Content-Encoding 字段表示数据的压缩方法,表示服务器响应的数据使用了什么压缩格式。
如下图所示,采用了 gzip 压缩格式:

和 Content-Type 类似,Content-Encoding 在请求中也有一个对应的字段 Accept-Encoding,表示客户端能接收的压缩格式有哪些。
如下所示,能接收 gzip,deflate,br 压缩格式:

5. HTTP 常见状态码
HTTP 有五大类状态码,如下所示:

下面介绍一些常见的状态码。
2XX — 成功:
- 200 OK:请求 正常处理
- 204 No Content:请求处理成功,但 没有资源可返回
- 206 Partial Content:对某资源的 部分请求,表示客户端进行了范围请求,响应报文中包含由 Content-Range 指定范围的实体内容
3XX — 重定向:
- 301 Moved Permanently:永久重定向 — 资源的 URI 已更新,让客户端也更新下
- 302 Found:临时重定向 — 资源的 URI 临时定位到了其他的位置
- 304 Not Modified:与重定向无关,自从上次访问后,服务器对该资源没有做过改变,让浏览器 使用未过期的本地缓存
4XX — 客户端错误:
- 400 Bad Request:服务器 无法理解该请求,请求报文可能有语法错误
- 401 Unauthorized:没有请求权限,通常浏览器会弹出一个对话框,让用户进行登录认证
- 403 Forbidden:不允许访问该资源,请求的资源被服务器拒绝了
- 404 Not Found:服务器上 不存在该资源,可能是路径错误等
5XX — 服务端错误:
- 500 Internal Server Error:服务器内部资源出现故障,可能是服务端出现了 Bug 等
- 502 Bad Gateway:网关错误,在软件架构中网关通常指用于分发请求的代理服务,如 Nginx 作为代理接收请求,再分发到后面的具体服务器。502 指代理服务器正常,但是 代理要去访问源站时发生了错误,代理服务器接收到无效的响应
- 503 Service Unavailable:服务器正忙,说明服务器超负载或停机维护了
- 504 Gateway Timeout:网关超时,指代理服务器请求源服务器超时了
6. HTTP 请求方法
6.1 常见 HTTP 请求方法
HTTP 请求方法一览:
| 方法 | 说明 |
|---|---|
| GET | 请求指定的资源,用于数据的读取 |
| HEAD | 类似于 GET,只是不返回主体部分,只返回响应头,用于确认 URL 的有效性和测试服务器的性能 |
| POST | 向指定资源 提交数据,请求服务器 创建资源,如:表单数据提交、文件上传等,请求数据会被包含在请求体中。 |
| PUT | 客户端请求的数据 替换 服务端的目标资源,但资源不存在时也会创建资源 |
| DELETE | 删除 指定的资源 |
| PATCH | PUT 方法的补充,对资源进行 局部更新 |
6.2 幂等和安全的方法
什么是幂等?
HTTP 方法的幂等性是指 一次和多次请求某一个资源,得到的结果是相同的。
在 HTTP 方法中,具有幂等性的方法有如下:
- GET:GET 方法用于获取资源,不会对资源产生其他影响,因此是幂等的;
- DELETE:DELETE 方法用于删除资源,虽然会对资源产生影响,但是也满足幂等性。因为 调用一次和多次对该资源产生的影响是相同的。
POST 和 PUT 单独介绍,因为他们比较容易混淆。
首先要明确一点,POST 和 PUT 都能够创建资源,PUT 方法在资源不存在时也会创建该资源。
它们都能创建资源,主要 区别 在于:
- N 次 POST 请求,就会 创建 N 份资源,它们具有 不同的 URI;
- N 次 PUT 请求,只会在资源不存在时才创建一份资源,后面的 N - 1 次 PUT 请求只会进行修改,只是修改前和修改后的资源相同罢了;
因此,POST 和 PUT 的幂等性也很容易判断出来了,即 POST 不具有,而 PUT 具有。
幂等性也是 POST 和 PUT 的 真正区别。
什么是安全?
HTTP 方法的安全性指的是 请求方法不会改变服务器的状态,则该方法是安全的。
所以具有安全性的方法就只能用于 只读操作,即 GET 和 HEAD。
当然,除了这些常见的方法,还有一些其他方法,例如 OPTIONS 和 TRACE 也是安全的。